for each, iterable, iterator, ListIterator에 대하여
Iterator는 콜렉션 프레임워크에 저장된 요소들을 읽어오는 표준화된 방법으로 자바 1.2에서 추가되었다. 거두절미하고 Iterator는 어떻게 사용되는지 코드를 보자.
iterator()
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
Iterator<String> itr = list.iterator();
while(itr.hasNext()) {
String item = itr.next();
System.out.println(item);
}iterator는 콜렉션 혹은 배열의 데이터를 순차적으로 읽어올 때 구현하는 반복문을 더 쉽게 만들어준다. 콜렉션 객체에서 iterator()를 호출해 반복문에 적용해 사용할 수 있다. hasNext를 호출하여 다음 데이터가 있는지 확인하고 있다면 next()로 다음 위치에 있는 데이터를 읽어오는 것이다.
하지만 위와 같이 사용하는 사람들은 잘 없을 것이다. 다음 코드를 보자.
for each
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
for(String str : list)
System.out.println(str);for each로 콜렉션의 데이터를 읽어 오는 방법이다. 아마 자바 콜렉션에서 제공하는 자료구조를 자주 사용해봤다면 이러한 형태의 반복문을 사용해 본 적이 있을 것이다. iterator의 예제를 보여주고 바로 for each를 보여주는 이유는 for each를 가능하게 해주는 것이 iterator, iterable이기 때문이다. 이렇듯 iterator는 두 가지 방식으로 사용할 수 있는데 for each를 사용하는 편이 더 쉽고 직관적이기 때문에 for each가 일반적으로 사용된다.
일반적으로 for each가 더 많이 쓰이지만 그럼에도 불구하고 iterator를 호출하여 사용하는 경우가 있다. iterator는 기본적으로 데이터를 읽어오는 도중 자료구조에 영향을 끼치는 것을 코드적으로 허용하지 않고 있기 때문에 컬렉션에서 제공하는 add(..), remove(..) 등의 메서드를 호출할 수 없다. 그럼에도 불구하고 반복자로 데이터를 읽는 중, 특정 데이터에 대한 삭제, 수정을 해야할 경우가 있기 때문에 iterator는 데이터 삭제를 위해 파라미터가 없는 remove() 메서드를 제공한다.
for each와 iterator의 차이는 iterator를 명시적으로 사용하는가, 아닌가에 대한 차이라고 볼 수 있다. for each로 데이터를 읽어올 때에는 개발자가 직접 iterator를 호출하지 않고 컴파일러가 적절하게 hasNext, next를 호출하며 데이터를 읽어오기 때문에 코드가 훨씬 간단해진다는 장점이 있지만 remove 메서드는 컴파일러가 알아서 호출해줄 수 없기에 사용할 수 없다. 반대로 명시적으로 iterator를 읽어올 경우 hasNext와 next 같은 메서드들을 직접 구현해야 한다는 단점이 있지만 remove 같은 메서드를 개발자가 원하는 타이밍에 적절하게 사용할 수 있다는 장점이 있다.
데이터를 오로지 읽기만 한다면 for each가, 특정 데이터를 찾아 삭제까지 필요하다면 iterator 객체를 받아 쓰면 될 것이다.
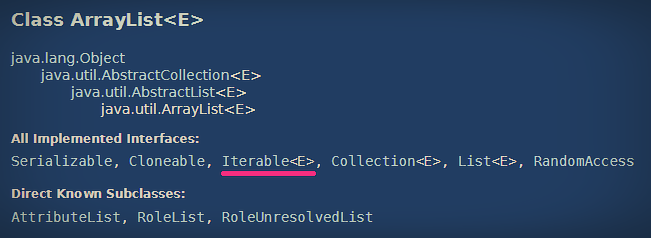
컬렉션에서 자주 사용되는 자료구조 중 하나인 ArrayList를 보자. 위 캡쳐는 오라클에서 제공하는 ArrayList에 대한 API 문서 중 일부를 발췌한 것이다. 위 캡쳐본에서 ArrayList가 구현(implements)하고 있는 인터페이스 중 Iterable이 포함되어 있는 것을 볼 수 있다. 컬렉션에서 iterator를 사용하기 위해서는 iterator() 메서드를 호출해 객체를 넘겨받아야 하는데, 이 메서드를 가지고 있는 것이 Iterable interface이며 이 인터페이스가 없다면 for each도 수행할 수 없기 때문에 iterator에 앞서 이 인터페이스를 먼저 구현해야 한다.
iterator와 iterable은 컬렉션의 데이터를 읽어오는 표준이지만 반드시 컬렉션에서만 사용가능한 것이 아니며 직접 구현하여 사용할 수 있다. 지금부터 iterable과 iterator를 구현하는 것에 대해 알아보자.
Iterator 구현하기
for each를 적용시킬 클래스에 iterable interface를 구현할 것이다. 실제로 for each를 사용할 때 반환하는 것은 iterator를 구현한 클래스를 객체화하여 넘겨준다. 일반적으로 데이터를 저장, 관리할 메인이 되는 자료구조 클래스와 이 클래스에 적용될 iterator를 구현한 내부 클래스로 작성한다.
implements Iterable
for each를 구현하기 전에 간단한 테스트를 해볼 것이다. 먼저 아래와 같이 제네릭 타입의 파라미터 1개를 가진 클래스를 생성한 뒤 메인 메서드에서 for each 형태로 호출해 결과를 보자.
public class MyList<E> { }
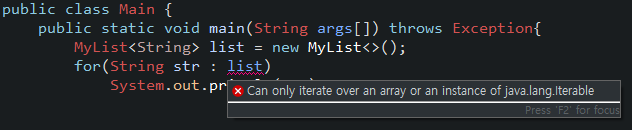
일단 클래스 내부에 아무 코드도 없기 때문에 데이터를 읽어올 수 없는 것은 당연하다. 에러 메시지를 보면 for each를 사용할 수 있는 것은 배열 혹은 java.lang.iterable을 상속한 클래스만 가능하다는 것을 확인할 수 있다. 그럼 이제 클래스에 Iterable interface를 구현해보자.
import java.util.Iterator;
public class MyList<E> implements Iterable<E>{
@Override
public Iterator<E> iterator() {
// TODO Auto-generated method stub
return null;
}
}Iterable interface를 구현(implements)하면 클래스에 밑줄이 그이며 아직 구현되지 않은 메서드가 있다고 알려준다. 클래스 명에 마우스를 올리고 "Add unimplemented methods" 메시지를 클릭하면 아래와 같은 메서드가 추가되는 것을 볼 수 있다. for each나 iterator를 호출하면 이 메서드가 호출된다.
이제 코드를 저장한 뒤 다시 메인 메서드로 돌아가보면 에러 메시지가 사라진 것을 확인할 수 있다.
물론 다시 돌아가 for each를 수행하면 에러(java.lang.NullPointerException)가 발생한다. 아무것도 작성하지 않았기 때문이다. 더 정확히 말하자면 iterator() 메서드가 null을 반환하고 있기 때문이다.(확인해 보고 싶다면 try-catch로 감싸고 실행시켜 보자.) 이제 for each가 가능하도록 클래스를 작성해보자.
implements Iterator
import java.util.ConcurrentModificationException;
import java.util.Iterator;
public class MyList<E> implements Iterable<E>{
final int DEFAULT_CAPACITY = 10;
Object[] elementData;
int size;
int modCount;
MyList() {
elementData = new Object[DEFAULT_CAPACITY];
}
public boolean add(E e) {
if(size == 10)
return false;
elementData[size++] = e;
modCount++;
return true;
}
@SuppressWarnings("unchecked")
public E remove(int index) {
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index "
+ index + "out of bounds for length " + size);
E oldElement = (E)elementData[index];
if(index != size-1)
for(int i = index; i < size-1; i++)
elementData[i] = elementData[i+1];
elementData[--size] = null;
modCount++;
return oldElement;
}
@Override
public Iterator<E> iterator() {
return new MyIterator<E>();
}
class MyIterator<E> implements Iterator<E> {
int cursor;
int lastRefer = -1;
int expectedModCount = modCount;
@Override
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
@Override
public E next() {
checkForSync();
return (E)elementData[lastRefer = cursor++];
}
@Override
public void remove() {
if(lastRefer < 0)
throw new IllegalStateException();
checkForSync();
MyList.this.remove(lastRefer);
lastRefer = -1;
expectedModCount = modCount;
}
private void checkForSync() {
if(modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
MyList class의 코드는 꼭 필요한 것만으로 최소화하였다. ArrayList처럼 내부에서 데이터를 저장하기 위한 배열 elementData을 사용하고, 객체화될 때 생성자에서 기본 값 10으로 고정적인 크기의 배열을 할당받는다. 그리고 add(E)를 통해 데이터를 10개 까지 삽입할 수 있고, remove(int)를 통해 특정 인덱스의 데이터를 제거할 수 있다.
핵심이 되는 부분은 MyIterator class다. 이 클래스는 for each를 구현하거나 MyList의 iterator()를 호출하였을 때 객체화되어 반환된다. 먼저 각 메서드의 역할에 대해 알아보자.
hasNext()
다음 참조할 값이 있는지 판단한다. 판단하는 기준은 현재 데이터 개수(size)와 현재 참조중인 위치(cursor)를 비교하여 같으면 false, 다르면 true를 반환한다.
next()
단독으로 호출하기 보다는 hasNext()로 true를 리턴받아 데이터가 있다고 판단되었을 때 호출한다. 먼저 checkForSync로 자료구조의 변형을 확인한다. 그 후 다음 반환할 데이터를 찾기 위해 배열을 참조할 때 cursor의 값을 lastRefer에 저장한 뒤 cursor의 값을 후증가로 1증가 시킨다. 이렇게 하는 이유는 데이터 반환이 끝났을 때 lastRefer는 마지막에 참조한 위치를, cursor는 다음 참조할 위치를 가르키게 하기 위함이다.
remove()
해당 메서드는 ArrayList에서 사용하던 데이터 삭제 메서드인 remove(int index), remove(Object o)와 달리 파라미터가 없다. 특정 요소를 참조하여 삭제하라고 명시할 수 없다는 것인데, 오라클에서 제공하는 API Document에 따르면 Iterator에서 remove를 사용할 때에는 "마지막에 반환한 데이터를 삭제한다"고 에 명시되어 있다.
이제 메서드를 들여다보자. next() 메서드를 호출하지 않은 상태에서 remove를 호출하는 경우, remove를 2번 호출하는 경우를 막기 위해서 가장 먼저 lastRefer가 0보다 작은지 확인한다. lastRefer가 0 이상이라는 것은 이전에 참조한 값을 가리키고 있다는 것이다. 그 후 checkForSync를 호출하여 자료구조 변형을 확인한다. 문제가 없을 경우 MyList의 remove(int index)를 호출하여 마지막에 참조한 값을 가리키고 있는 lastRefer를 파라미터로 넘겨 삭제를 수행한다.
이제 후처리를 봐야하는데 cusor에 lastRefer의 값을 복사한다. cursor는 다음 참조할 위치를 가지고 있는데 remove를 수행함으로써 데이터가 모두 1개씩 당겨졌음으로 cursor의 크기도 1 감소할 필요가 있다. 또한 방금 참조한 위치의 값이 사라졌기 때문에 remove()가 연속으로 2번 호출되면 cursor와 lastRefer의 값이 같아져 아직 참조하지도 않은 값을 삭제하거나 범위를 벗어나는 오류가 발생할 수 있기 때문에 -1을 초기화하여 에러를 방지한다.
remove는 Iterator를 수행하는 도중 유일하게 데이터 변경을 허용하는 메서드다. 여기서 expectedModCount 변수를 고려해야 하는데 modCount의 값을 증가시키는 remove(int index)를 호출했기 때문에 expectedModCount와 modCount의 값이 일치하지 않게 된다. 때문에 expectedModCount의 값을 현재 modCount로 바꿔주는 것 까지가 remove 메서드의 역할이다.
클래스를 만들고 iterator를 implements해 보았다면 눈치챘겠지만 이 메서드는 필수 구현 메서드가 아니다. "Override/implements method.." 옵션을 통해 필요하다면 추가할 수 있다. 이 메서드가 선택적 구현인 이유는 위에서 말했듯 for each만을 사용할 경우 remove는 어차피 호출될 일이 없기 때문이다.
checkForSync()
next(), remove() 메서드가 호출될 때 지역 초반에 호출되어 자료구조의 변형 여부를 확인한다.
Example) iterator

백문이 불여일견이니 iterator를 사용한 예제를 보며 역할을 보자. list에 데이터를 5개 삽입한 후 리스트를 읽어오기 위해 list의 iterator() 메서드를 통해 MyIterator 객체를 받아온다. 그리고 while loop를 돌면서 데이터를 읽어오는데, 반복 조건을 판단할 때 hasNext() 메서드로 참조할 위치(cursor)와 현재 데이터 개수(size)를 비교하여 다음 참조할 값이 있는지 판단한다. 값이 있을 경우 next() 메서드를 호출하여 다음 값을 읽어온다. 읽어온 문자열을 비교하여 "banana"라면 삭제하고 이 외는 출력한다.
Example) for each
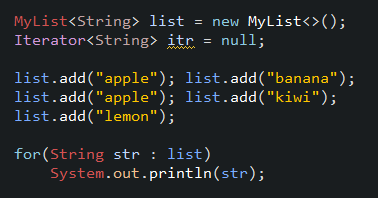
다음은 for each를 사용한 예제다. iterator와 비교해봐도 명백히 쉽고 간단하다. 예제처럼 데이터를 읽으면 컴파일러가 hasNext와 next를 적절하게 사용해 간편한 대신 remove를 사용할 수 없다.
컬렉션이 아닌 클래스에서 Iterator를 구현해 사용하는 것에 대해 알아보았다. iterator를 구현하면 for each로 데이터를 순방향으로 조회하는 것이 가능하고 iterator 객체를 반환받아 사용하는 경우 여기서 추가로 remove가 가능하다. 그리고 여기에 더해 순방향, 역방향으로 조회가 가능하면서 데이터 삽입, 삭제, 수정 등이 추가된 ListIterator interaface가 있다.
'자바 > 자바' 카테고리의 다른 글
| [Java] 데이터 클래스 구분 (VO, DTO, Entity) (0) | 2022.01.11 |
|---|---|
| [자바] Iterator를 구현할 때 고려해야 할 문제 (0) | 2021.12.28 |
| [자바] 반복문을 더 쉽게, for each 사용하기 (0) | 2021.12.27 |
| [자바] Collection Framework (0) | 2021.12.26 |
| [Java] Buffer 클래스의 flush, close 메서드 (0) | 2021.12.06 |