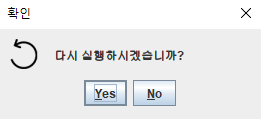
자바 Swing에서 경고창 혹은 의사 결정(확인/취소)을 위한 확인창으로 JOptionPane이 존재한다. 위 캡쳐에 나온 화면은 ErrorMessage 아이콘을 사용한 것인데 이 아이콘을 커스텀해보자.
위는 자바에서 기본적으로 제공하는 아이콘이다. 나는 개인적으로 쓰는 프로그램에 경고창을 띄우던 중 기본 아이콘들이 너무 옛날 느낌을 주기도 하고 상황에 맞게 사용할 수 있는 아이콘이 매우 제한적이라는 생각이 들어 커스텀을 찾아보게 되었다.
import java.awt.Image;
import javax.swing.ImageIcon;
import javax.swing.JOptionPane;
public class JOptionPaneTest {
public static void main(String[] args) {
ImageIcon originIcon = new ImageIcon("res//arrow_cycle.png");
Image resizeImg = originIcon.getImage().getScaledInstance(30, 30, Image.SCALE_SMOOTH);
ImageIcon icon = new ImageIcon(resizeImg);
JOptionPane.showConfirmDialog(null, "다시 실행하시겠습니까?", "확인", JOptionPane.YES_NO_OPTION, JOptionPane.PLAIN_MESSAGE, icon);
}
}
메시지 창을 띄우기 위해 굳이 JFrame까지 사용할 필요는 없다. 위처럼 해주기만 해도 메시지 창을 띄울 수 있다. 테스트에 사용된 이미지 파일은 프로젝트 폴더에 "res" 폴더를 생성한 뒤 안에 넣어주었다.
ImageIcon 객체를 생성하고 프로젝트 폴더에 추가한 이미지 파일을 불러온다. 예제에 사용한 이미지 파일은 메시지 창에 쓰기에는 꽤나 크기 때문에 그대로 사용하면 이미지 크기가 들어가는 만큼 메시지 창이 컵져 버리기 때문에 조절이 필요하다. 아이콘으로 쓰기 적당한 파일 크기는 30x30 ~ 50x50이기 때문에 적절히 값을 바꾸어 가며 맞는 값을 찾으면 된다. 코드에서 리사이즈 작업을 해줘도 되지만 그림판, 포토샵 등으로 이미지 파일의 자체 크기를 조정해줘도 된다.
아이콘을 설정했으면 JOptionPane에서 원하는 타입의 다이얼로그(메서드)를 선택한 다음, Icon 객체를 파라미터로 받는 (오버로딩된)메서드를 선택하고 인자로 ImageIcon 객체를 넘겨준다. 그리고 프로그램을 실행하면 아래와 같은 결과를 얻을 수 있다.
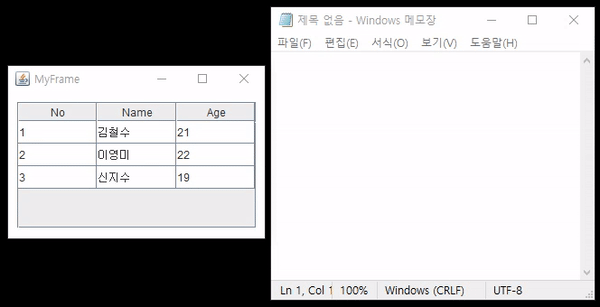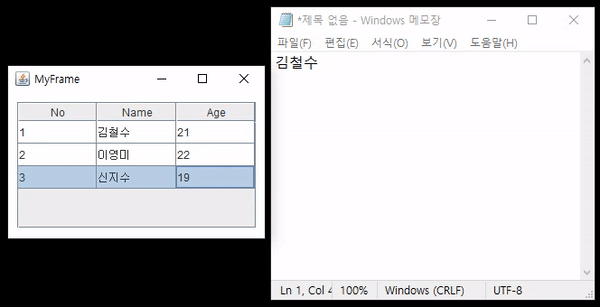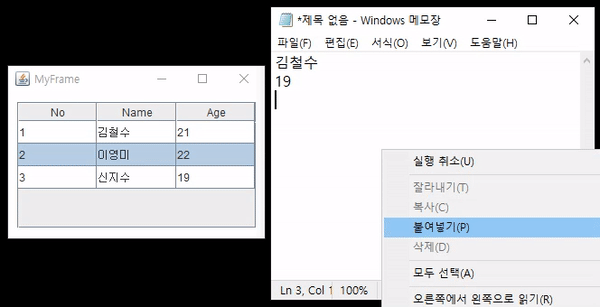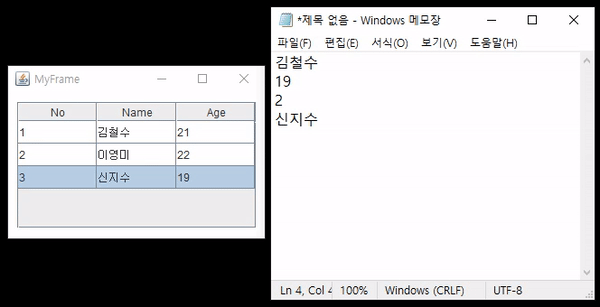
JTable에 있는 값을 더블 클릭했을 때 해당하는 값을 복사해보자. 위 gif에서는 커서가 보이지 않기 때문에 무엇을 클릭하는지 자세히 보이지 않을 수 있는데 자세히 보면 클릭되는 셀의 테두리가 굵게 되는 것을 볼 수 있다.
기본적으로 JFrame, JTable을 다룰 줄 알아야 하고 MouseListener 혹은 MouseAdapter를 사용할 줄 알면 좋다. 전체 코드를 포스팅에 포함시킬 예정이지만 테이블 생성에 관한 기본적인 설명은 하지 않는다.
MouseListener는 인터페이스이기 때문에 마우스의 핵심적인 이벤트(드래그, 이동, 클릭 전후) 메서드를 강제적으로 구현해야 하지만 아답터를 쓰면 필요한 메서드만을 오버라이드하여 사용할 수 있다. 현재 구현에 있어서는 클릭한 후 이벤트만 필요하기 때문에 리스너가 아닌 아답터를 사용하여 구현할 것이다. 아답터를 사용할 줄 모른다면 리스너로 구현해도 문제없다.
테이블에서 선택된 값, 문자열을 복사하면 클립보드(Clipboard)에 저장된다. 클립보드에 대해 깊게 알 필요는 없고 우리가 복사한 값이 클립보드에 저장되고 복사한 값을 읽어올 때에는 붙여넣기(혹은 Ctrl+V)를 통해 클립보드에서 꺼내온다는 것만 알면 되겠다.
아래는 코드다.
import java.awt.Color;
import java.awt.Toolkit;
import java.awt.datatransfer.Clipboard;
import java.awt.datatransfer.StringSelection;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
import java.util.ArrayList;
import javax.swing.JFrame;
import javax.swing.JScrollPane;
import javax.swing.JTable;
import javax.swing.ListSelectionModel;
import javax.swing.table.DefaultTableModel;
public class MyFrame extends JFrame{
private JTable jtab;
private DefaultTableModel dtm;
private Clipboard clipboard;
private ArrayList<Person> list;
private final String[] TABLE_HEADER = {"No", "Name", "Age"};
public static void main(String[] args) {
MyFrame myFrame = new MyFrame();
myFrame.setVisible(true);
}
public MyFrame() {
setTitle("MyFrame");
setBounds(10, 10, 300, 200);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
getContentPane().setBackground(Color.white);
setLayout(null);
clipboard = Toolkit.getDefaultToolkit().getSystemClipboard();
setComponent();
setTable();
}
private void setComponent() {
dtm = new DefaultTableModel(TABLE_HEADER, 0) {
@Override
public boolean isCellEditable(int row, int column) {
return false;
}
};
jtab = new JTable(dtm);
jtab.getTableHeader().setReorderingAllowed(false);
jtab.getTableHeader().setEnabled(false);
jtab.setSelectionMode(ListSelectionModel.SINGLE_SELECTION);
jtab.setRowHeight(25);
jtab.addMouseListener(new MouseAdapter() {
@Override
public void mouseClicked(MouseEvent e) {
super.mouseClicked(e);
if (e.getClickCount() == 2) {
int row = jtab.getSelectedRow();
int col = jtab.getSelectedColumn();
StringSelection value = null;
switch(col) {
case 0:
value = new StringSelection(list.get(row).no + "");
break;
case 1:
value = new StringSelection(list.get(row).name);
break;
case 2:
value = new StringSelection(list.get(row).age + "");
}
clipboard.setContents(value, value);
}
}
});
JScrollPane tablePan = new JScrollPane(jtab, JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED,
JScrollPane.HORIZONTAL_SCROLLBAR_NEVER);
tablePan.setBounds(10, 10, 265, 140);
add(tablePan);
}
private void setTable() {
list = new ArrayList<>();
list.add(new Person(1, "김철수", 21));
list.add(new Person(2, "이영미", 22));
list.add(new Person(3, "신지수", 19));
for(Person person : list)
dtm.addRow(person.toArray());
}
class Person {
int no, age;
String name;
public Person(int no, String name, int age) {
this.no = no;
this.name = name;
this.age = age;
}
public Object[] toArray() {
return new Object[] {no, name, age};
}
}
}
기본적인 코드만 존재하기 때문에 JTable을 한 번이라도 생성해봤다면 코드를 어렵지 않게 이해할 수 있을 것이다. 데이터 클래스인 Person의 경우 예제 코드를 줄이기 위해서 getter를 생략하였다. 핵심은 멤버 변수인 Clipboard 객체와 JTable 객체에 마우스 이벤트를 추가한 addMouseListener 메서드가 되겠다.
JTable에 추가된 값을 마우스로 클릭했을 때 이벤트를 발생시키기 위해서 MouseAdapter를 추가한 뒤 마우스 이벤트 중 클릭이 때어진 순간 이벤트를 발생시키는 mouseClicked 메서드를 오버라이드 한다. 여기서 더블 클릭을 구현하기 위해서 getClickCount를 통해 연속으로 클릭된 횟수를 체크하여 2번 클릭되었을 경우에 이벤트를 처리한다.
더블 클릭이 발생하면 먼저 클릭된 행(row), 열(column)의 인덱스를 구한다. 행은 리스트의 인덱스로 사용되고 열은 리스트에서 읽어온 객체에서 특정한 값을 읽는데 사용될 것이다. 값을 읽었으면 StringSelection 객체에 초기화한 후 해당 객체를 클립보드에 세팅한다. 여기까지 문제없이 수행되었다면 클립보드에 값이 복사되었을 것이다. 텍스트를 입력할 수 있는 곳(메모장 등)에다가 "붙여넣기" 혹은 Ctrl+v를 수행하면 값이 복사된 것을 확인할 수 있다.
모든 멤버 변수에 대한 getter 메서드가 반드시 존재해야 하며 값을 변경할 수 있는 setter 메서드는 생성하면 안된다.
생성자 중 모든 멤버 변수를 파라미터로 가지는 생성자는 반드시 존재해야 한다. 객체를 생성하고 나면 데이터를 초기화할 수 없기 때문이다.
멤버 변수에 final 키워드를 사용해 변경할 수 없도록 한다.
타 데이터 클래스와 구분하기 위하여 패키지로 분류하거나 접미사로 "*VO.java"를 붙여 구분한다.
DTO(Data Transfer Object)
MVC와 같은 계층 구조에서 계층간 데이터를 주고 받을 때 꼭 필요한 데이터만을 가지는 클래스다.
네트워크를 통해 클라이언트(혹은 서버)의 요청에 따라 DB로부터 읽어온 객체에 불필요한 데이터가 있을 경우 꼭 필요한 데이터만으로 구성된 DTO 클래스로 재구성하여 전송한다.
타 데이터 클래스와구분하기 위하여패키지로 분류하거나 접미사로 "*DTO.java"를 붙여 구분한다.
Entity
데이터베이스에서 데이터를 읽어올 때 테이블의 구조(속성들)와 일치하는 구조를 갖는 클래스.
데이터베이스에서 레코드 단위로 값을 읽어올 때 레코드 1개가 하나의 데이터 클래스로 대응될 수 있어야 한다.
타 데이터 클래스와구분하기 위하여패키지로 분류하거나 접미사로 "*Entity.java"를 붙여 구분한다.
데이터 클래스들은 "*.data.entity"와 같이 전용 패키지를 생성하여 관리하는 것이 좋다. 프로젝트의 규모가 커지면 커질수록 늘어나는 데이터 클래스들의 관리가 어려워진다.
세 클래스는 데이터를 저장하기 위해 설계된 클래스라는 공통점이 있지만 목적에 따라 다른 특성을 가져야 하기 때문에 같은 대상이라도 여러 개의 데이터 클래스를 생성할 수 있다. 예를 들어 사용자가 내가 서비스 중인 어플에서 개인 정보를 열람하려 할 때 스마트폰을 이용 중인 사람이 본인이 아닐 수 있기에 최소한으로만 보여줄 필요가 있다. 다른 사람들에게 보여지는 닉네임, 이름, 아이디 등은 공개할 수 있지만 비밀번호는 노출되어서는 안되고 인증 수단(이메일, 휴대폰 번호) 역시 쉽게 노출되선 안되므로 인증을 거친 뒤 보여주는 것이 일반적이다. 하지만 일반적으로 이러한 데이터들은 모두 하나의 테이블에서 관리되므로 디비에서 데이터를 읽어 오면 모든 데이터가 들어 있다. 이러한 경우 먼저 특정 레코드를 Entity 클래스로 받은 뒤 사용자에게 보낼 데이터는 DTO 클래스로 재구성하여 보내는 것이다.
Iterator(이하 반복자)를 사용해 컬렉션의 데이터를 읽어올 때 고려해야 할 점이 있다. 순회하는 도중 자료구조 변경이 일어나서는 안된다는 것인데 만약 순회 도중 자료구조가 변경될 경우 "java.util.ConcurrentModificationException" 예외가 발생한다. 이 예외는 어떤 상황에 발생하는지, 컬렉션에서는 어떻게 처리하는지 ArrayList를 통해 알아보자.
에러가 발생하는 상황
java.util.ConcurrentModificationException
내가 코딩을 하다 에러가 발생했을 당시 코드 구조를 대략적으로 표현해보았다. ArrayList와 Iterator를 선언 후 list에서 iterator()를 호출해 미리 객체를 받아온다. 그리고 list에 데이터를 삽입 후 반복자로 데이터를 읽어오는 것이다.
위 코드를 try-catch로 감싸고 실행시키면, while문의 첫 번째 라인에서 데이터를 읽어오기 위해 next() 메서드를 호출하는 순간 예외가 발생한다.
"반복자로 요소를 순회하는 중에 자료구조가 변경되면 안된다"
처음에 이 에러에 대해서 구글링해 보았을 때 많은 글에서 "순회 중에"라는 문구를 공통적으로 봤었기 때문에 while이 시작한 후로 문제점을 분석했다. 에러를 마주했을 당시 코드는 위 예제처럼 짧지 않았고 while문으로 감싸진 구역 안 그 몇 줄 사이에 문제가 있을거라 생각하고 코드를 보았지만 문제가 발견되지 않았다. 때문에 ArrayList에서 반복자가 구현되어 있는 부분을 뜯어보았다.
반복자가 왜 에러를 일으키는지 알아보려면 먼저 내부에서 어떻게 동작하는지 알아야 한다. ArrayList에서 for each문 혹은 iterator() 메서드를 호출하면 내부 클래스 Itr을 객체화하여 넘겨준다. 여기서 Itr 클래스가 가진 멤버 변수의 역할을 보면 다음과 같다.
cursor : 다음 리턴할 요소의 위치를 가리킴 (init to 0)
lastRet : 마지막으로 리턴한 요소의 위치를 가리킴 (init to -1)
expectedModCount : iterator 메서드가 호출되어 itr class가 객체화 된 시점에서 elementData 배열의 데이터가 변경된 횟수
Itr class - cursor, lastRet
ArrayList는 내부적으로 배열(elementData)을 가지고 데이터를 관리하는데, iterator로 이 배열을 순회할 때 다음 참조할 위치를 가리키는 변수로 cursor를 사용한다.
next method
next 메서드는 다음 값을 반환하는 메서드다. cursor를 i에 복사한 후 1 증가시키는 것으로 cursor는 다음 위치를 가리키도록 한다. cursor의 이전 값이 저장되어 있는 변수 i로 elementData를 참조하는 동시에 lastRet에 i를 저장한다. 이 메서드가 종료되었을 때 cursor는 다음 참조할 위치, lastRet은 이전에 참조한 위치를 가리키고 있게 되는 것이다.
이 메서드가 처음 호출되었을 때 cursor는 0, 이전에 참조한 값이 없기 때문에 lastRet은 -1을 가리키고 있는 상태에서 시작한다. 먼저 i에 cursor의 값(0)을 복사한 후 cursor를 1증가시키는 것으로 cursor는 다음 참조할 위치인 1을 가르키게 된다. 그리고 cursor의 이전값을 가진 i로 elementData를 참조하는 동시에 lastRet에 i을 저장하여 lastRet이 마지막 참조한 위치 0를 갖게 되는 것이다. 여기까지 보면 왜 굳이 lastRet이라는 변수를 사용하는 것인가에 대한 의문이 들 것이다. lastRet의 쓰임은 remove 메서드를 보면 알 수 있다.
remove method
remove() 메서드는 이름에서 유추할 수 있듯이 컬렉션 내의 특정 요소를 삭제하는 역할을 한다. 다만 파라미터가 없기 때문에 호출할 때 객체나 인덱스를 넘겨 특정 위치를 지우는 것이 불가능하고 마지막에 next()로 반환된 위치에 있는 데이터를 삭제하는 역할을 한다. lastRet이 현재 위치를 가리키고 있기 때문에 내부에서 remove(int index) 메서드를 호출, 파라미터로 lastRet을 전달하는 것으로 마지막으로 반환된 위치의 데이터를 삭제한다.
Itr class - expectedModCount
위의 두 변수가 반환할 다음 값을 찾고, 삭제하는 역할을 했다면 이 변수는 에러를 확인하는 역할을 한다. 이 변수는 객체화될 때 modCount라는 변수의 값으로 초기화되는데, modCount는 ArrayList의 슈퍼 클래스인 AbstractList(추상화 클래스)에서 상속받은 변수다. ArrayList에서 특정 메서드가 수행될 때마다 modCount의 값이 1 증가, 즉 카운팅되며 해당하는 메서드는 다음과 같다.
(메서드는 자바 버전마다 상이할 수 있음, 오버로딩 된 메서드를 제외하고 총 11개)
trimToSize
ensureCapacity
add
fastRemove
clear
addAll
removeRange
replaceAll
sort
checkInvariants
이 메서드들은 배열의 사이즈를 직접 증감시키거나 데이터를 추가/삭제하는 등 자료구조를 변화시키는 메서드들이다. 살펴본 메서드들의 역할을 근거로 modCount는 현재까지 자료구조가 변경된 횟수라는 것을 알 수 있다. 즉, expectedModCount는 Itr class가 객체화 될 때 현재까지 자료구조가 변경된 횟수로 초기화된다는 것이다. (set 메서드와 같은 값 변경은 자료구조 변경으로 보지 않음.)
이렇게 초기화 된 expectedModCount는 Itr class 내에서 다음과 같이 사용된다.
expectedModCount
먼저 checkForComodification() 메서드를 보자. 이 메서드는 현 시점 modCount의 값과 클래스가 객체화될 때의 modCount 값을 비교하는데 값이 다를 경우 ArrayList의 데이터가 변경되었다고 판단하고 예외롤 반환한다. next, remove 메서드가 호출될 때 내부에서 호출되어 예외 여부를 체크한다.
다시 remove() 메서드를 보자. 아까는 언급하지 않았지만 "expectedModCount = modCount"라는 코드가 보인다. remove 메서드를 호출하면 마지막에 참조한 위치(lastRet)의 값이 삭제된다고 했다. 이 메서드는 ArrayList의 내부 메서드인 remove(int index)를 호출하는데, itr가 허락하는 삭제라고 해도 이 또한 자료구조의 변화이기 때문에 정상적으로 수행될 경우 modCount가 증가하기 때문에 증가 된 modCount를 expectedModCount에 업데이트시켜 준다.
이제까지 분석한 것을 통해 다음과 같은 결론을 도출할 수 있다.
"Collection에서 iterator()를 호출한 시점으로부터 자료구조 변형이 일어날 경우 예외가 발생한다."
java.util.ConcurrentModificationException
예외를 일으키는 조건을 알았으니 다시 글 초반에 게시한 에러가 난 코드를 보자. 이 코드에서 에러가 난 이유는 반복자를 ArrayList를 객체화한 후 바로 얻어왔고, 그 후 데이터 삽입이 일어났기 때문이다. list를 객체화한 직후 modCount는 0이기 때문에 itr를 객체화하였을 때 expectedModCount 또한 0으로 초기화된다. 후에 add() 메서드를 10회 호출하여 modCount가 10이 되었기 때문에 modCount와 expectedModCount의 값이 서로의 값이 일치하지 않게 되어 에러가 발생한 것이다.
예제처럼 iterator를 앞단에 선언하더라도 루프로 데이터를 읽어오기 전에 iterator를 호출하여 사용하는 것이 가장 확실할 것이다. 또한 당연하게도 반복 중 컬렉션에서 제공하는 자료구조에 변화를 일으키는 메서드를 호출해서는 안된다.
iterator 사용 중 컬렉션에 수정해야 할 일이 생길 경우
iterator는 데이터를 읽는 와중에 삭제를 할 수 있도록 파라미터가 없는 remove() 메서드를 제공한다. 이는 object나 index를 파라미터로 받는 기존 컬렉션의 remove가 아닌 iterator 내부에서 제공하는 메서드다. 이 외에도 양방향 데이터 순회가 가능하면서 remove에 더하여 set, add 기능을 제공하는 ListIterator를 사용하는 것도 하나의 방법이겠다.
Iterator는 콜렉션 프레임워크에 저장된 요소들을 읽어오는 표준화된 방법으로 자바 1.2에서 추가되었다. 거두절미하고 Iterator는 어떻게 사용되는지 코드를 보자.
iterator()
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
Iterator<String> itr = list.iterator();
while(itr.hasNext()) {
String item = itr.next();
System.out.println(item);
}
iterator는 콜렉션 혹은 배열의 데이터를 순차적으로 읽어올 때 구현하는 반복문을 더 쉽게 만들어준다. 콜렉션 객체에서 iterator()를 호출해 반복문에 적용해 사용할 수 있다. hasNext를 호출하여 다음 데이터가 있는지 확인하고 있다면 next()로 다음 위치에 있는 데이터를 읽어오는 것이다.
하지만 위와 같이 사용하는 사람들은 잘 없을 것이다. 다음 코드를 보자.
for each
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
for(String str : list)
System.out.println(str);
for each로 콜렉션의 데이터를 읽어 오는 방법이다. 아마 자바 콜렉션에서 제공하는 자료구조를 자주 사용해봤다면 이러한 형태의 반복문을 사용해 본 적이 있을 것이다. iterator의 예제를 보여주고 바로 for each를 보여주는 이유는 for each를 가능하게 해주는 것이 iterator, iterable이기 때문이다. 이렇듯 iterator는 두 가지 방식으로 사용할 수 있는데 for each를 사용하는 편이 더 쉽고 직관적이기 때문에 for each가 일반적으로 사용된다.
일반적으로 for each가 더 많이 쓰이지만 그럼에도 불구하고 iterator를 호출하여 사용하는 경우가 있다. iterator는 기본적으로 데이터를 읽어오는 도중 자료구조에 영향을 끼치는 것을 코드적으로 허용하지 않고 있기 때문에 컬렉션에서 제공하는 add(..), remove(..) 등의 메서드를 호출할 수 없다. 그럼에도 불구하고 반복자로 데이터를 읽는 중, 특정 데이터에 대한 삭제, 수정을 해야할 경우가 있기 때문에 iterator는 데이터 삭제를 위해 파라미터가 없는 remove() 메서드를 제공한다.
for each와 iterator의 차이는 iterator를 명시적으로 사용하는가, 아닌가에 대한 차이라고 볼 수 있다. for each로 데이터를 읽어올 때에는 개발자가 직접 iterator를 호출하지 않고 컴파일러가 적절하게 hasNext, next를 호출하며 데이터를 읽어오기 때문에 코드가 훨씬 간단해진다는 장점이 있지만 remove 메서드는 컴파일러가 알아서 호출해줄 수 없기에 사용할 수 없다. 반대로 명시적으로 iterator를 읽어올 경우 hasNext와 next 같은 메서드들을 직접 구현해야 한다는 단점이 있지만 remove 같은 메서드를 개발자가 원하는 타이밍에 적절하게 사용할 수 있다는 장점이 있다.
데이터를 오로지 읽기만 한다면 for each가, 특정 데이터를 찾아 삭제까지 필요하다면 iterator 객체를 받아 쓰면 될 것이다.
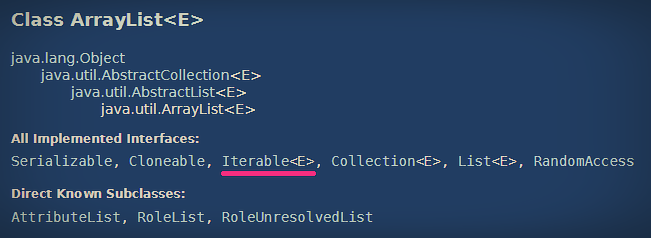
컬렉션에서 자주 사용되는 자료구조 중 하나인 ArrayList를 보자. 위 캡쳐는 오라클에서 제공하는 ArrayList에 대한 API 문서 중 일부를 발췌한 것이다. 위 캡쳐본에서 ArrayList가 구현(implements)하고 있는 인터페이스 중 Iterable이 포함되어 있는 것을 볼 수 있다. 컬렉션에서 iterator를 사용하기 위해서는 iterator() 메서드를 호출해 객체를 넘겨받아야 하는데, 이 메서드를 가지고 있는 것이 Iterable interface이며 이 인터페이스가 없다면 for each도 수행할 수 없기 때문에 iterator에 앞서 이 인터페이스를 먼저 구현해야 한다.
iterator와 iterable은 컬렉션의 데이터를 읽어오는 표준이지만 반드시 컬렉션에서만 사용가능한 것이 아니며 직접 구현하여 사용할 수 있다. 지금부터 iterable과 iterator를 구현하는 것에 대해 알아보자.
Iterator 구현하기
for each를 적용시킬 클래스에 iterable interface를 구현할 것이다. 실제로 for each를 사용할 때 반환하는 것은 iterator를 구현한 클래스를 객체화하여 넘겨준다. 일반적으로 데이터를 저장, 관리할 메인이 되는 자료구조 클래스와 이 클래스에 적용될 iterator를 구현한 내부 클래스로 작성한다.
implements Iterable
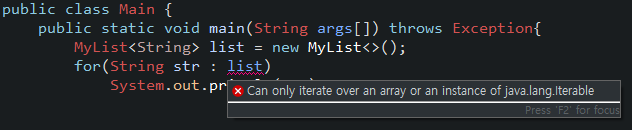
for each를 구현하기 전에 간단한 테스트를 해볼 것이다. 먼저 아래와 같이 제네릭 타입의 파라미터 1개를 가진 클래스를 생성한 뒤 메인 메서드에서 for each 형태로 호출해 결과를 보자.
public class MyList<E> { }
error : Can only iterate over an array or an instance of java.lang.Iterable
일단 클래스 내부에 아무 코드도 없기 때문에 데이터를 읽어올 수 없는 것은 당연하다. 에러 메시지를 보면 for each를 사용할 수 있는 것은 배열 혹은 java.lang.iterable을 상속한 클래스만 가능하다는 것을 확인할 수 있다. 그럼 이제 클래스에 Iterable interface를 구현해보자.
import java.util.Iterator;
public class MyList<E> implements Iterable<E>{
@Override
public Iterator<E> iterator() {
// TODO Auto-generated method stub
return null;
}
}
Iterable interface를 구현(implements)하면 클래스에 밑줄이 그이며 아직 구현되지 않은 메서드가 있다고 알려준다. 클래스 명에 마우스를 올리고 "Add unimplemented methods" 메시지를 클릭하면 아래와 같은 메서드가 추가되는 것을 볼 수 있다. for each나 iterator를 호출하면 이 메서드가 호출된다.
이제 코드를 저장한 뒤 다시 메인 메서드로 돌아가보면 에러 메시지가 사라진 것을 확인할 수 있다.
물론 다시 돌아가 for each를 수행하면 에러(java.lang.NullPointerException)가 발생한다. 아무것도 작성하지 않았기 때문이다. 더 정확히 말하자면 iterator() 메서드가 null을 반환하고 있기 때문이다.(확인해 보고 싶다면 try-catch로 감싸고 실행시켜 보자.) 이제 for each가 가능하도록 클래스를 작성해보자.
implements Iterator
import java.util.ConcurrentModificationException;
import java.util.Iterator;
public class MyList<E> implements Iterable<E>{
final int DEFAULT_CAPACITY = 10;
Object[] elementData;
int size;
int modCount;
MyList() {
elementData = new Object[DEFAULT_CAPACITY];
}
public boolean add(E e) {
if(size == 10)
return false;
elementData[size++] = e;
modCount++;
return true;
}
@SuppressWarnings("unchecked")
public E remove(int index) {
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index "
+ index + "out of bounds for length " + size);
E oldElement = (E)elementData[index];
if(index != size-1)
for(int i = index; i < size-1; i++)
elementData[i] = elementData[i+1];
elementData[--size] = null;
modCount++;
return oldElement;
}
@Override
public Iterator<E> iterator() {
return new MyIterator<E>();
}
class MyIterator<E> implements Iterator<E> {
int cursor;
int lastRefer = -1;
int expectedModCount = modCount;
@Override
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
@Override
public E next() {
checkForSync();
return (E)elementData[lastRefer = cursor++];
}
@Override
public void remove() {
if(lastRefer < 0)
throw new IllegalStateException();
checkForSync();
MyList.this.remove(lastRefer);
lastRefer = -1;
expectedModCount = modCount;
}
private void checkForSync() {
if(modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
MyList class의 코드는 꼭 필요한 것만으로 최소화하였다. ArrayList처럼 내부에서 데이터를 저장하기 위한 배열 elementData을 사용하고, 객체화될 때 생성자에서 기본 값 10으로 고정적인 크기의 배열을 할당받는다. 그리고 add(E)를 통해 데이터를 10개 까지 삽입할 수 있고, remove(int)를 통해 특정 인덱스의 데이터를 제거할 수 있다.
핵심이 되는 부분은 MyIterator class다. 이 클래스는 for each를 구현하거나 MyList의 iterator()를 호출하였을 때 객체화되어 반환된다. 먼저 각 메서드의 역할에 대해 알아보자.
hasNext()
다음 참조할 값이 있는지 판단한다. 판단하는 기준은 현재 데이터 개수(size)와 현재 참조중인 위치(cursor)를 비교하여 같으면 false, 다르면 true를 반환한다.
next()
단독으로 호출하기 보다는 hasNext()로 true를 리턴받아 데이터가 있다고 판단되었을 때 호출한다. 먼저 checkForSync로 자료구조의 변형을 확인한다. 그 후 다음 반환할 데이터를 찾기 위해 배열을 참조할 때 cursor의 값을 lastRefer에 저장한 뒤 cursor의 값을 후증가로 1증가 시킨다. 이렇게 하는 이유는 데이터 반환이 끝났을 때 lastRefer는 마지막에 참조한 위치를, cursor는 다음 참조할 위치를 가르키게 하기 위함이다.
remove()
해당 메서드는 ArrayList에서 사용하던 데이터 삭제 메서드인 remove(int index), remove(Object o)와 달리 파라미터가 없다. 특정 요소를 참조하여 삭제하라고 명시할 수 없다는 것인데, 오라클에서 제공하는 API Document에 따르면 Iterator에서 remove를 사용할 때에는 "마지막에 반환한 데이터를 삭제한다"고 에 명시되어 있다.
이제 메서드를 들여다보자. next() 메서드를 호출하지 않은 상태에서 remove를 호출하는 경우, remove를 2번 호출하는 경우를 막기 위해서 가장 먼저 lastRefer가 0보다 작은지 확인한다. lastRefer가 0 이상이라는 것은 이전에 참조한 값을 가리키고 있다는 것이다. 그 후 checkForSync를 호출하여 자료구조 변형을 확인한다. 문제가 없을 경우 MyList의 remove(int index)를 호출하여 마지막에 참조한 값을 가리키고 있는 lastRefer를 파라미터로 넘겨 삭제를 수행한다.
이제 후처리를 봐야하는데 cusor에 lastRefer의 값을 복사한다. cursor는 다음 참조할 위치를 가지고 있는데 remove를 수행함으로써 데이터가 모두 1개씩 당겨졌음으로 cursor의 크기도 1 감소할 필요가 있다. 또한 방금 참조한 위치의 값이 사라졌기 때문에 remove()가 연속으로 2번 호출되면 cursor와 lastRefer의 값이 같아져 아직 참조하지도 않은 값을 삭제하거나 범위를 벗어나는 오류가 발생할 수 있기 때문에 -1을 초기화하여 에러를 방지한다.
remove는 Iterator를 수행하는 도중 유일하게 데이터 변경을 허용하는 메서드다. 여기서 expectedModCount 변수를 고려해야 하는데 modCount의 값을 증가시키는 remove(int index)를 호출했기 때문에 expectedModCount와 modCount의 값이 일치하지 않게 된다. 때문에 expectedModCount의 값을 현재 modCount로 바꿔주는 것 까지가 remove 메서드의 역할이다.
클래스를 만들고 iterator를 implements해 보았다면 눈치챘겠지만 이 메서드는 필수 구현 메서드가 아니다. "Override/implements method.." 옵션을 통해 필요하다면 추가할 수 있다. 이 메서드가 선택적 구현인 이유는 위에서 말했듯 for each만을 사용할 경우 remove는 어차피 호출될 일이 없기 때문이다.
checkForSync()
next(), remove() 메서드가 호출될 때 지역 초반에 호출되어 자료구조의 변형 여부를 확인한다.
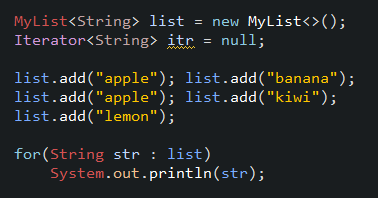
Example) iterator
백문이 불여일견이니 iterator를 사용한 예제를 보며 역할을 보자. list에 데이터를 5개 삽입한 후 리스트를 읽어오기 위해 list의 iterator() 메서드를 통해 MyIterator 객체를 받아온다. 그리고 while loop를 돌면서 데이터를 읽어오는데, 반복 조건을 판단할 때 hasNext() 메서드로 참조할 위치(cursor)와 현재 데이터 개수(size)를 비교하여 다음 참조할 값이 있는지 판단한다. 값이 있을 경우 next() 메서드를 호출하여 다음 값을 읽어온다. 읽어온 문자열을 비교하여 "banana"라면 삭제하고 이 외는 출력한다.
Example) for each
다음은 for each를 사용한 예제다. iterator와 비교해봐도 명백히 쉽고 간단하다. 예제처럼 데이터를 읽으면 컴파일러가 hasNext와 next를 적절하게 사용해 간편한 대신 remove를 사용할 수 없다.
컬렉션이 아닌 클래스에서 Iterator를 구현해 사용하는 것에 대해 알아보았다. iterator를 구현하면 for each로 데이터를 순방향으로 조회하는 것이 가능하고 iterator 객체를 반환받아 사용하는 경우 여기서 추가로 remove가 가능하다. 그리고 여기에 더해 순방향, 역방향으로 조회가 가능하면서 데이터 삽입, 삭제, 수정 등이 추가된 ListIterator interaface가 있다.
자바에서 사용할 수 있는 반복문으로 for와 while이 있다. Java 5 부터는 for문을 좀 더 쉽게 사용할 수 있도록 for each문이라는 것을 제공한다. 새로운 예약어를 사용하지 않고 기존 for문을 조금 변형하여 사용한다.
기존 for문과 for each문을 비교해보자.
for
public static void main(String args[]) {
String[] fruit = {"apple", "banana", "melon", "kiwi", "orange"};
for(int i = 0; i < fruit.length; i++)
System.out.println(fruit[i]);
}
for each
public static void main(String args[]) {
String[] fruit = {"apple", "banana", "melon", "kiwi", "orange"};
for(String s : fruit)
System.out.println(s);
}
String 타입의 배열에 있는 값을 모두 출력시키는 코드다. 한 눈에 보기에도 간결해진 것을 알 수 있다. 기존의 for문을 보면 초기식, 반복조건, 증감식의 형태를 가지는데 for each 문을 보면 반복되는 동안 가져올 값을 저장할 변수와 값을 꺼내 올 대상을 지정하는 것만으로 반복을 수행할 수 있다. 위 예제는 배열을 대상으로 하였는데 자바에서 제공하는 컬렉션을 대상으로도 for each를 사용할 수 있다.
for each와 Collection
컬렉션이 for each를 수행할 수 있는 이유는 Iterable interface를 구현하고 있기 때문이다. 반복 수행 방법은 배열과 다르지 않지만 컬렉션의 경우 List, Set, Queue, Map 중 Map은 단일 객체가 아닌 Key, Value 쌍으로 데이터를 저장하고 있기 때문에 사용 방법이 조금 다르다.
ArrayList, HashSet
public static void main(String args[]) {
List<String> list = new ArrayList<>();
Set<Integer> set = new HashSet<>();
// add elements..(skip)
for(String s : list) // ArrayList
System.out.println(s);
for(int n : set)
System.out.println(n);
}
HashMap
public static void main(String args[]) {
Map<String, Integer> map = new HashMap<>();
// add elements..(skip)
// entrySet() 메서드를 사용하는 경우
for(Map.Entry<String, Integer> e : map.entrySet())
System.out.println("K : " + e.getKey() + ", V : " + e.getValue());
// keySet() 메서드를 사용하는 경우
for(String key : map.keySet()) {
int value = map.get(key);
System.out.println("K : " + key + ", V : " + value);
}
}
Map의 경우 일반적인 for each와 달리 위와 같이 사용한다. Key와 Value가 모두 필요한 경우 entrySet() 메서드를, Key만 필요한 경우 keySet을 사용한다.
for와 for each 적절하게 쓰기
기존 for문은 익숙하지 않으면 반복 조건의 비교문이나 반복조건의 증감식을 작성할 때 잘못된 식을 적어 오류를 일으키는 경우가 종종 있는데 for each문은 그러한 오류를 미연에 방지할 수 있다는 장점이 있다. 하지만 더 쉽게 쓸 수 있는 for each가 등장했다고 해서 기존 for문을 사용하지 않는 것은 아니다. for each는 현재 접근 중인 위치를 모르기 때문에 순회 중 발견한 데이터를 수정/삭제하기가 까다롭기 때문에 데이터를 찾아서 수정/삭제하는 목적이라면 기존 for문을 사용하는 것이 더 나을 수 있다.
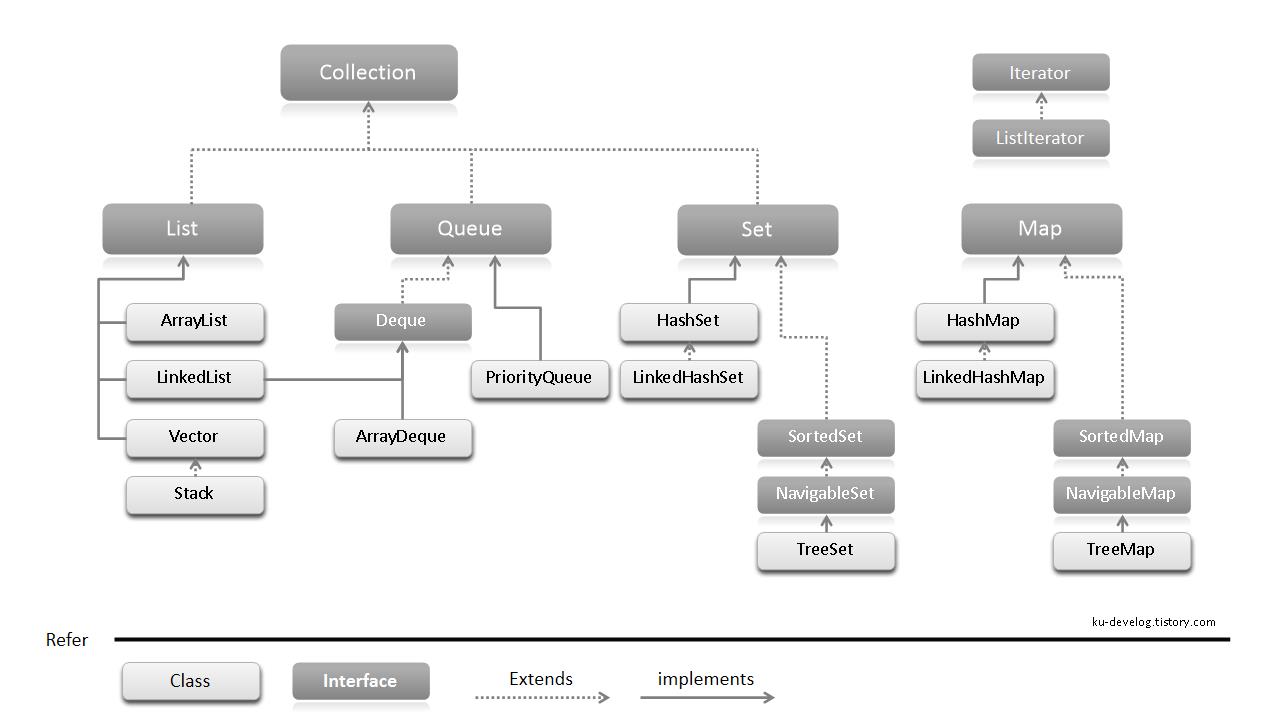
자바에서는 데이터를 쉽고 간단하게, 상황에 맞게 효율적으로 저장할 수 있도록 표준화 된 클래스(자료구조)를 제공하는데 이러한 클래스의 집합을 컬렉션 프레임워크라고 한다. 큰 범주로 보면 List, Set, Queue, Map 등으로 나눌 수 있다. 알고리즘도 그렇듯 어느 상황, 환경에서든 항상 뛰어난 성능을 보이는 자료구조는 없다. 모두 장단점이 있고 좋은 상황과 나쁜 상황이 있기 때문에 상황에 맞는 자료구조를 골라서 사용해야 한다.
인터페이스 별 특징
Collection : 주로 컬렉션 간의 이루어지는 작업을 담당한다. 컬렉션끼리 데이터를 복사하거나, 서로 가진 데이터를 비교하는 등 컬렉션 사이에 일어나는 메서드들을 다룬다.
List : 순서가 있는 데이터의 집합으로 중복되는 데이터를 허용한다.
Set : 순서가 없는 데이터의 집합으로 중복된 데이터를 허용하지 않는다.
Map : List, Set과 다른 저장방식을 취한다. Key-Value 쌍으로 데이터를 저장한다. 키는 중복을 허용하지 않지만 값은 중복을 허용한다.
Queue : 데이터가 들어온 순서대로 출력되는 FIFO 구조를 갖는다. 대표적인 예로 운영체제 스케쥴러가 있다.
iterator : 컬렉션에 데이터를 읽어오기 위한 인터페이스다. 루프를 돌려 get 메서드로 데이터를 순서대로 읽어올 수도 있지만 해당 인터페이스를 구현하면 for-each문으로 데이터를 읽어올 수 있다.
Collection에서의 Interface와 class의 관계
Interface는 설계도일 뿐이다. 어떤 인터페이스를 구현(implemets)하는 클래스는 반드시 설계도(interface)에 나와있는 메서드를 구현(override)해야 한다. List는 Collection을 상속(extends)받고 ArrayList는 List를 구현(implements)하였기 때문에 ArrayList는 Collection과 List가 가진 메서드들을 반드시 구현해야한다.
이렇게 해서 얻는 효과는 무엇일까? Collection이 가진 주요 메서드로 isEmpty(), clear() 등이 있는데 이 메서드들은 Collection을 구현한 ArrayList, HashMap, Stack 등 모든 자료구조에서 공통적으로 사용할 수 있다. 자료구조의 특성에 따라 내부에서 처리하는 방식은 다르지만 사용할 때 데이터가 비어 있는지 확인할 땐 isEmpty()를, 데이터를 초기화할 땐 clear()를 사용한다는 것은 동일하다.
다음과 같은 상황을 가정해보자. 어떤 기능을 구현할 때 ArrayList를 사용해서 데이터를 저장했었지만 구현해놓고 보니 LinkedList가 더 적합해보여서 LinkedList로 변경하려 한다. ArrayList는 내부적으로 배열을 사용하고 LinkedList는 Node를 사용하는데 구조가 전혀 다름에도 불구하고 각 자료구조 고유의 메서드를 몇 개 제외하면 Collection, List를 구현할 때 사용한 메서드를 둘 다 똑같이 구현하고 있으므로 최소한의 수정으로 자료구조를 교체할 수 있는 것이다.
또한 선언시에 자료구조 타입을 상위 인터페이스인 List로 선언할 경우 코드를 전혀 수정하지 않고 위처럼 한 번만 수정해서 자료구조를 바꾸는 것도 가능하다. 다만 이 경우에는 ArrayList가 가진 고유의 메서드를 사용하지 않았다는 가정이 필요하다. 즉 ArrayList를 사용할 때 Collection, List 등 LinkedList와 공통적으로 구현한 인터페이스에 속한 메서드만 사용한 경우, 위와 같은 한 번에 자료구조 교체가 가능하다는 것이다. 이를 업 캐스팅이라 한다.
BufferedWriter, FileWriter와 같이 중간에 버퍼를 두고 사용하는 클래스는 버퍼를 비우기 위한 목적으로 flush() 메서드를 제공한다. 스트림을 통해 데이터를 출력할 때 마지막에 데이터를 누락시키지 않으려면 flush가 꼭 필요하다고 생각했는데 막상 버퍼를 두는 클래스의 예제를 찾아 보면 flush를 사용하지 않는 경우도 많았다. 사용하고 안하고의 차이가 궁금했기에 flush에 대해 조사해봤다.
스트림으로 연결된 두 지점이 있을 때 사용자의 입력이 발생할 경우 즉시 데이터를 출력하지 않고 데이터를 축적하다가 일정량만큼 쌓이면 출력한다. 여기서 데이터를 축적하는 곳이 버퍼이며 한정된 자원인 메모리에 데이터를 무작정 계속 쌓을 수는 없기에 초기의 버퍼의 크기를 정해놓는다. 버퍼의 크기만큼 데이터가 축적되면 내부에서 자동으로 버퍼를 비우도록 되어 있기 때문에 사용 중에 버퍼가 얼마나 찼는지 고려할 필요가 없다. 다만 축적되는 데이터의 총량이 버퍼의 크기로 딱 나누어 떨어질 확률은 거의 없기 때문에 스트림 사용이 끝났을 때 버퍼에 데이터가 남아 있을 확률이 매우 높다. 이러한 경우 flush()를 호출하여 남아 있는 데이터를 방출하는 것이다.
flush()를 사용하지 않는 경우는 무엇일까? 바로 close()를 호출하는 것이다. 스트림은 네트워크, 파일, 입출력을 수행할 때 연결하는 데이터를 주고 받는 통로라고 볼 수 있다. 그리고 스트림은 운영체제의 자원을 가져다 쓰는 것이므로 사용하고 나면 반납을 해야 하는데 이 때 close() 메서드를 호출하여 사용한 자원을 해제한다. 버퍼를 사용하는 클래스들도 마찬가지로 스트림을 사용하기 때문에 마지막에 close()를 호출하는데 이 때 내부적으로 flush()를 호출하여 버퍼에 남아 있을지도 모르는 데이터를 강제적으로 방출한다.
다시 한 번 버퍼가 비워지는 시점을 정리하면 다음과 같다.
버퍼의 크기만큼 데이터가 쌓였을 때
코드에서 flush()를 호출했을 때
코드에서 close()를 호출했을 때
정리하자면 flush를 사용하지 않았던 예제들은 어차피 스트림을 닫으면 close()에서 자동으로 flush()를 호출할 것이니 flush()를 굳이 호출하지 않아도 된다는 생각이었던 것이다.(단순히 까먹었을 수도 있다..)
하지만 작업이 끝나는 시점과 close()를 호출하는 시점이 바로 이어지지 않고 중간에 다른 작업을 수행하게 되면 어떻게 될까? 다음 같은 상황을 가정해보자.
단순히 순서상으로 보면 "ABC" 가 나와야 할 것 같지만 코드를 실행시켜보면 "ACB"가 나온다. 코드를 보면 "A"를 write 한 다음 flush를 해주었으니 버퍼에서 대기하던 "A"가 가장 먼저 출력된다. 그리고 "B"를 write 하였는데 이전에 막 버퍼를 비웠기 때문에 퍼버가 자동으로 비워질 일도 없고 flush(), close()도 호출해주지 않았기 때문에 "B"는 버퍼에 남아 있는 상태로 유지된다. 그리고 "C"를 출력한 뒤 try{..} 지역의 코드가 끝나고 마지막으로 finally에서 스트림을 close() 해준다. close에서 자원을 정리하기 전에 버퍼에 남아 있던 "B"를 출력했기 때문에 결과로 "ACB"가 나온 것이다.
flush()를 호출하지 않아도 close()에서 버퍼를 비워주는 것은 맞다. 하지만 위 예제에서 알 수 있듯이 스트림 사용이 끝나는 시점과 close()를 호출하는 시점이 바로 이어지지 않을 경우 의도한 것과 다른 결과가 나올 수 있다는 것이다. 매번 중간에 다른 작업이 있는가에 대해 신경쓸 바에야 flush()랑 close()를 항상 사용해주는 습관을 들이는 것이 좋겠다.