ArrayList는 자바를 공부하면서 가장 많이 사용되는 자료구조 중 하나다. 본 포스팅에서는 ArrayList가 왜 필요한지, 내부적으로 어떻게 동작되는지에 대한 이론을 다룬다. ArrayList는 배열을 기반으로 하기 때문에 먼저 배열에 대한 이해를 필요로 하기 때문에 배열에 대해 간단히 리뷰한 뒤 ArrayList에 대해 알아보고 다음 포스팅인 구현으로 넘어 가겠다.
배열(Array), 그리고 문제점
프로그래밍을 공부하다 보면 초기에 배열(Array)이라는 것을 배우게 된다. 변수가 여러 개 필요할 때 일일이 "int a, b, c.. etc"와 같이 선언해야 한다면 접근하기도 관리하기도 쉽지 않다. 변수가 2, 3개라면 모를까 10개 20개, 몇 백 개가 된다면 사실상 관리가 불가능하기 때문에 같은 성질의 변수가 여러 개일 경우 배열을 사용하게 된다.
변수를 할당받으면 메모리 영역 중 스택에 할당받게 되는데, 변수는 변수명으로만 접근할 수 있기 하기 때문에 변수의 수가 많을 수록 유기적으로 접근하기가 어렵다. 특히 반복문을 통해 같은 성질의 데이터들 탐색하는 것은 엄청난 노가다가 될 것이다. 하지만 배열의 경우 Heap 영역에 메모리를 연속적으로 할당받은 뒤 배열의 시작 주소를 스택에 저장해서 접근할 수 있다. 메모리 상에 데이터가 연속적으로 할당되어 있다는 것은 가장 앞 주소만 기억하고 있다면 다음 데이터가 있는 위치는 배열의 자료형 크기를 더해주는 것으로 주소를 알아낼 수 있다는 것을 의미한다. 이러한 구조는 성격이 비슷한 변수들의 관리를 용이하게 해주고, 간단한 주소 계산을 통해 배열의 어느 요소든 빠른 접근을 가능하게 한다.
하지만 장점이 있으면 단점도 존재한다. 배열은 한 번 할당받으면 크기를 줄이거나 늘일 수 없고, 저장된 데이터가 정렬되어 있다고 할 때 중간의 데이터를 삽입 및 삭제하려고 하면 해당 인덱스를 기준으로 데이터를 밀거나 당기는 작업이 필요해진다. 또한 배열을 초기화할 때 할당받은 메모리를 전부 사용한 상황에서 새로운 데이터를 삽입하려고 하면 공간 부족의 문제가 발생한다. 공간이 부족할 수 있으니 미리 넉넉하게 할당받아 놓는다는 생각을 할 수 있지만 추후 데이터 삽입 여부에 따라 공간 낭비로 이어질 수 있다.
데이터의 개수가 정해져 있고 삭제/삽입이 일어나지 않는 환경이라고 한다면 접근이 빠른 배열이 유리하지만 데이터 삭제/삽입이 빈번하고 데이터의 개수가 유동적인 상황이라면 배열은 결코 좋은 해결 방법이 될 수 없다.
그렇다면 빠른 접근이라는 장점을 유지한 채로 정적인 배열을 동적으로 사용할 수 없을까?
ArrayList
위에서 배열의 개념과 장단점을 살펴봤다. 배열은 데이터 삽입/삭제가 잦고 데이터 개수가 유동적인 환경에 적합하지 않다.
ArrayList를 한마디로 표현하면 "사이즈 변경이 가능한 배열"이라고 할 수 있다. ArrayList는 배열의 요소에 접근할 때 대괄호([n])를 사용하지 않고 메서드를 통해서 보다 직관적인 데이터 삽입/삭제/변경을 할 수 있다. 또한 배열에 있는 데이터를 초기화하거나 배열 내 데이터 검색 등 사용자에게 편리한 메서드를 제공한다. 이러한 메서드들의 존재는 사용자가 직접 작성하면서 발생할 수 있는 자잘한 오류를 방지해주는 효과도 있다. 하지만 처음에 언급했듯이 가장 큰 장점은 내부적으로 배열을 사용함에도 불구하고 데이터 개수 제한에 구애받지 않고 얼마든지 데이터를 삽입할 수 있다는 점이다.(여기서 메모리 크기의 한계는 생각하지 않는다.) ArrayList는 이름에서 유추할 수 있듯 내부를 들여다보면 배열을 사용하고 있다. 내부적으로 배열을 사용함에도 불구하고 어떻게 데이터를 무한히 삽입할 수 있는 것일까?
아래 소스코드는 실제 ArrayList 클래스의 일부분을 가져온 것인데 Object형 배열 elementData가 실제로 우리가 add를 호출해서 데이터를 삽입하면 데이터가 저장된다. 소스를 이해하라는 것이 아닌 내부에 배열을 쓰고 있다는 것만을 보고 가면 되겠다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
@java.io.Serial
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
...
}
ArrayList에서 배열 크기 문제를 해결하는 방법
final int DEFAULT_CAPACITY = 5;
int[] array = new int[DEFAULT_CAPACITY];크기 5의 배열 array를 선언하였다. 만약 위 배열에 데이터가 5개 삽입되었다고 가정한다면 배열의 최대 크기만큼 데이터가 삽입되었기 때문에 더 이상 데이터가 삽입될 수 없는 상태가 된다. 일반적인 배열이라면 여기서 기존 데이터를 유지한 채 새로운 데이터를 삽입하는 방법은 없다.

ArrayList의 경우를 보자. ArrayList는 초기에 일정한 크기의 배열을 할당받아 놓는다. 사용자가 초기 배열의 크기를 지정해 줄 수도 있지만 지정해주지 않아도 기본값으로 배열이 생성된다. 예를 들어 기본값이 5라고 하면 크기 5의 배열이 생성될 것이다. 그리고 그 배열에 5개의 데이터가 삽입되었다고 하면 더 이상 데이터를 추가할 수 없는 상태가 될 것이다. 이것은 배열의 본질이기 때문에 변하지 않는다. 하지만 ArrayList는 가지고 있는 배열에 데이터를 한계까지 삽입한 경우 더 큰 크기의 새로운 배열을 만드는 것으로 문제점을 극복했다. 현재 배열의 크기보다 더 큰 배열을 만들어 현재 데이터를 모두 이동시킨 후 이제부터 새로 만든 배열을 사용하는 것이다.(이전 배열은 Unreachable Object가 되어 언젠가 가비지 콜렉터에게 수거당한다.) 소스코드로 보면 아래와 같다.
Object[] newArray = new Object[array.length * 2];
for(int i = 0; i < array.length; i++) {
newArray[i] = array[i];
array[i] = null;
}
array = newArray;새로운 배열을 생성하고 기존 데이터를 새로운 배열로 이동시키는 코드다. 데이터를 옮기는 작업이 끝나면 멤버 변수로 가지고 있던 메인 배열의 주소를 새로운 배열로 바꿔준다.
ArrayList 삽입, 삭제
그 외에 데이터 삽입, 삭제, 수정 등의 메서드도 지원한다. 배열을 사용하기 때문에 삽입, 삭제는 우리가 흔히 알고 있는 데이터를 뒤로 밀거나 앞으로 당기는 것으로 이루어진다. 메서드의 종류가 너무 많기에 간단히 삽입, 삭제에 대한 메서드만 소개하겠다.
add(Object value)

명실상부 ArrayList에서 가장 많이 사용되는 메서드로, 데이터를 삽입할 때 호출하며 파라미터로 전달한 값을 배열의 가장 마지막 위치에 삽입한다.
add(int index, Object value)
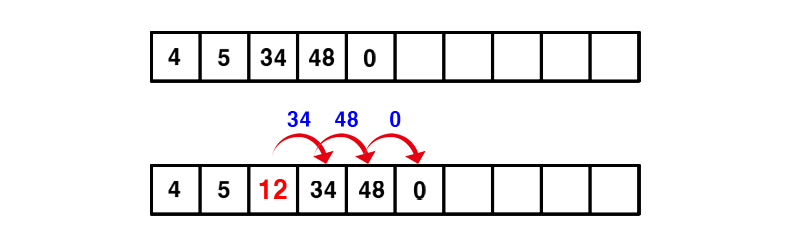
데이터를 삽입할 때 배열의 끝이 아니라 특정 위치에 데이터를 삽입해야 할 때가 있다. 만약 "ArrayList.add(2, 12)"라는 코드를 호출하게 되면 배열의 2번째 index에 12라는 값을 삽입하라는 뜻인데 해당 메서드가 호출될 경우 index 위치로부터 배열의 끝까지 데이터를 모두 뒤로 한칸씩 미루고 파라미터로 받은 값을 index 위치에 삽입한다.
remove(int index)
remove(Object value)

데이터를 삭제하는 방법은 크게 두 가지가 있다. 먼저 첫 번째 방법은 값으로 삭제할 데이터를 찾는 방법이다. remove 메서드의 파라미터로 Object를 넘긴 뒤 ArrayList가 가진 배열의 첫 번째 요소부터 마지막 데이터까지 비교해가며 해당 파라미터와 일치하는 값을 찾는다. 일치하는 값이 있을 경우 해당 위치를 기준으로 뒤에 있는 데이터를 한 칸씩 앞으로 당긴다.
두 번째 방법은 파라미터로 삭제할 데이터의 위치를 특정한 index를 받는 것이다. 삭제할 위치를 알고 있다면 배열의 장점인 index에 의한 접근으로 빠르게 데이터를 삭제할 수 있다. 값으로 데이터를 찾는 방법에 비해 탐색 시간은 없지만 뒤에 있는 값들을 하나씩 앞으로 당긴다는 점은 동일하기 때문에 어느 정도 부담이 가는 작업이다.
또한 값으로 데이터를 삭제하려할 때 배열에 해당하는 값이 없다면 null을 반환하지만 인덱스로 접근하는 경우 배열의 크기와 벗어난 경우 예외(Exception)이 발생하니 주의가 필요하다.
이 외에 데이터 수정(set), 배열 비우기(clear), 데이터 찾기 등 여러 기능을 지원하지만 여기서는 다루지 않고 다음 포스팅인 구현부에서 소스 코드와 함께 설명하겠다.
ArrayList
[자바/자료구조] ArrayList 직접 구현하기
본 포스팅에서는 ArrayList에 대한 보다 깊은 이해와 코딩 능력 상승을 위해 ArrayList를 구현합니다. ArrayList가 내부적으로 어떻게 동작하는지 모르신다면 코드를 보기 전에 ArrayList에 대한 이론을
ku-develog.tistory.com
'자료구조(Java) > 이론' 카테고리의 다른 글
| [자바/자료구조] 단일 연결 리스트(Singly Linked List) (0) | 2022.01.11 |
|---|---|
| [자바/자료구조] 연결 리스트(Linked List) (0) | 2022.01.11 |