Iterator(이하 반복자)를 사용해 컬렉션의 데이터를 읽어올 때 고려해야 할 점이 있다. 순회하는 도중 자료구조 변경이 일어나서는 안된다는 것인데 만약 순회 도중 자료구조가 변경될 경우 "java.util.ConcurrentModificationException" 예외가 발생한다. 이 예외는 어떤 상황에 발생하는지, 컬렉션에서는 어떻게 처리하는지 ArrayList를 통해 알아보자.
에러가 발생하는 상황

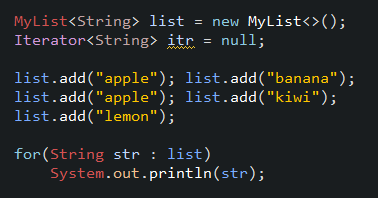
내가 코딩을 하다 에러가 발생했을 당시 코드 구조를 대략적으로 표현해보았다. ArrayList와 Iterator를 선언 후 list에서 iterator()를 호출해 미리 객체를 받아온다. 그리고 list에 데이터를 삽입 후 반복자로 데이터를 읽어오는 것이다.
위 코드를 try-catch로 감싸고 실행시키면, while문의 첫 번째 라인에서 데이터를 읽어오기 위해 next() 메서드를 호출하는 순간 예외가 발생한다.
"반복자로 요소를 순회하는 중에 자료구조가 변경되면 안된다"
처음에 이 에러에 대해서 구글링해 보았을 때 많은 글에서 "순회 중에"라는 문구를 공통적으로 봤었기 때문에 while이 시작한 후로 문제점을 분석했다. 에러를 마주했을 당시 코드는 위 예제처럼 짧지 않았고 while문으로 감싸진 구역 안 그 몇 줄 사이에 문제가 있을거라 생각하고 코드를 보았지만 문제가 발견되지 않았다. 때문에 ArrayList에서 반복자가 구현되어 있는 부분을 뜯어보았다.
ArrayList class에서의 iterator 동작
Itr class

(ArrayList의 동작 방식을 모른다면 이전 포스팅을 참조.)
(iterator의 동작 방식을 모른다면 이전 포스팅을 참조.)
반복자가 왜 에러를 일으키는지 알아보려면 먼저 내부에서 어떻게 동작하는지 알아야 한다. ArrayList에서 for each문 혹은 iterator() 메서드를 호출하면 내부 클래스 Itr을 객체화하여 넘겨준다. 여기서 Itr 클래스가 가진 멤버 변수의 역할을 보면 다음과 같다.
- cursor : 다음 리턴할 요소의 위치를 가리킴 (init to 0)
- lastRet : 마지막으로 리턴한 요소의 위치를 가리킴 (init to -1)
- expectedModCount : iterator 메서드가 호출되어 itr class가 객체화 된 시점에서 elementData 배열의 데이터가 변경된 횟수
Itr class - cursor, lastRet
ArrayList는 내부적으로 배열(elementData)을 가지고 데이터를 관리하는데, iterator로 이 배열을 순회할 때 다음 참조할 위치를 가리키는 변수로 cursor를 사용한다.

next 메서드는 다음 값을 반환하는 메서드다. cursor를 i에 복사한 후 1 증가시키는 것으로 cursor는 다음 위치를 가리키도록 한다. cursor의 이전 값이 저장되어 있는 변수 i로 elementData를 참조하는 동시에 lastRet에 i를 저장한다. 이 메서드가 종료되었을 때 cursor는 다음 참조할 위치, lastRet은 이전에 참조한 위치를 가리키고 있게 되는 것이다.
이 메서드가 처음 호출되었을 때 cursor는 0, 이전에 참조한 값이 없기 때문에 lastRet은 -1을 가리키고 있는 상태에서 시작한다. 먼저 i에 cursor의 값(0)을 복사한 후 cursor를 1증가시키는 것으로 cursor는 다음 참조할 위치인 1을 가르키게 된다. 그리고 cursor의 이전값을 가진 i로 elementData를 참조하는 동시에 lastRet에 i을 저장하여 lastRet이 마지막 참조한 위치 0를 갖게 되는 것이다. 여기까지 보면 왜 굳이 lastRet이라는 변수를 사용하는 것인가에 대한 의문이 들 것이다. lastRet의 쓰임은 remove 메서드를 보면 알 수 있다.

remove() 메서드는 이름에서 유추할 수 있듯이 컬렉션 내의 특정 요소를 삭제하는 역할을 한다. 다만 파라미터가 없기 때문에 호출할 때 객체나 인덱스를 넘겨 특정 위치를 지우는 것이 불가능하고 마지막에 next()로 반환된 위치에 있는 데이터를 삭제하는 역할을 한다. lastRet이 현재 위치를 가리키고 있기 때문에 내부에서 remove(int index) 메서드를 호출, 파라미터로 lastRet을 전달하는 것으로 마지막으로 반환된 위치의 데이터를 삭제한다.
Itr class - expectedModCount
위의 두 변수가 반환할 다음 값을 찾고, 삭제하는 역할을 했다면 이 변수는 에러를 확인하는 역할을 한다. 이 변수는 객체화될 때 modCount라는 변수의 값으로 초기화되는데, modCount는 ArrayList의 슈퍼 클래스인 AbstractList(추상화 클래스)에서 상속받은 변수다. ArrayList에서 특정 메서드가 수행될 때마다 modCount의 값이 1 증가, 즉 카운팅되며 해당하는 메서드는 다음과 같다.
(메서드는 자바 버전마다 상이할 수 있음, 오버로딩 된 메서드를 제외하고 총 11개)
- trimToSize
- ensureCapacity
- add
- fastRemove
- clear
- addAll
- removeRange
- replaceAll
- sort
- checkInvariants
이 메서드들은 배열의 사이즈를 직접 증감시키거나 데이터를 추가/삭제하는 등 자료구조를 변화시키는 메서드들이다. 살펴본 메서드들의 역할을 근거로 modCount는 현재까지 자료구조가 변경된 횟수라는 것을 알 수 있다. 즉, expectedModCount는 Itr class가 객체화 될 때 현재까지 자료구조가 변경된 횟수로 초기화된다는 것이다. (set 메서드와 같은 값 변경은 자료구조 변경으로 보지 않음.)
이렇게 초기화 된 expectedModCount는 Itr class 내에서 다음과 같이 사용된다.

먼저 checkForComodification() 메서드를 보자. 이 메서드는 현 시점 modCount의 값과 클래스가 객체화될 때의 modCount 값을 비교하는데 값이 다를 경우 ArrayList의 데이터가 변경되었다고 판단하고 예외롤 반환한다. next, remove 메서드가 호출될 때 내부에서 호출되어 예외 여부를 체크한다.
다시 remove() 메서드를 보자. 아까는 언급하지 않았지만 "expectedModCount = modCount"라는 코드가 보인다. remove 메서드를 호출하면 마지막에 참조한 위치(lastRet)의 값이 삭제된다고 했다. 이 메서드는 ArrayList의 내부 메서드인 remove(int index)를 호출하는데, itr가 허락하는 삭제라고 해도 이 또한 자료구조의 변화이기 때문에 정상적으로 수행될 경우 modCount가 증가하기 때문에 증가 된 modCount를 expectedModCount에 업데이트시켜 준다.
이제까지 분석한 것을 통해 다음과 같은 결론을 도출할 수 있다.
"Collection에서 iterator()를 호출한 시점으로부터 자료구조 변형이 일어날 경우 예외가 발생한다."
예외를 일으키는 조건을 알았으니 다시 글 초반에 게시한 에러가 난 코드를 보자. 이 코드에서 에러가 난 이유는 반복자를 ArrayList를 객체화한 후 바로 얻어왔고, 그 후 데이터 삽입이 일어났기 때문이다. list를 객체화한 직후 modCount는 0이기 때문에 itr를 객체화하였을 때 expectedModCount 또한 0으로 초기화된다. 후에 add() 메서드를 10회 호출하여 modCount가 10이 되었기 때문에 modCount와 expectedModCount의 값이 서로의 값이 일치하지 않게 되어 에러가 발생한 것이다.
예제처럼 iterator를 앞단에 선언하더라도 루프로 데이터를 읽어오기 전에 iterator를 호출하여 사용하는 것이 가장 확실할 것이다. 또한 당연하게도 반복 중 컬렉션에서 제공하는 자료구조에 변화를 일으키는 메서드를 호출해서는 안된다.
iterator 사용 중 컬렉션에 수정해야 할 일이 생길 경우
iterator는 데이터를 읽는 와중에 삭제를 할 수 있도록 파라미터가 없는 remove() 메서드를 제공한다. 이는 object나 index를 파라미터로 받는 기존 컬렉션의 remove가 아닌 iterator 내부에서 제공하는 메서드다. 이 외에도 양방향 데이터 순회가 가능하면서 remove에 더하여 set, add 기능을 제공하는 ListIterator를 사용하는 것도 하나의 방법이겠다.
오타, 의견, 질문 등의 댓글 받습니다.
'자바 > 자바' 카테고리의 다른 글
| [Java] 데이터 클래스 구분 (VO, DTO, Entity) (0) | 2022.01.11 |
|---|---|
| [자바] Iterator 구현하기 (for each 구현) (0) | 2021.12.27 |
| [자바] 반복문을 더 쉽게, for each 사용하기 (0) | 2021.12.27 |
| [자바] Collection Framework (0) | 2021.12.26 |
| [Java] Buffer 클래스의 flush, close 메서드 (0) | 2021.12.06 |