포스팅 1, 2에서 스프링 기초 환경과 mybatis 설정을 마쳤다. 테스트를 수행하기에 앞서 서버 생성과 관련하여 주의해야 할 부분을 몇 개 짚어보고 가자.
서버 추가하기
이클립스에 서버를 추가해보자. 콘솔이 있는 하단부에서 Servers 탭을 누르고 빈 공간에 우클릭, [New → Server]를 클릭한다.
도입부에 명시해놓았듯 Apache Tomcat 9.0을 사용하기 때문에 목록에서 톰캣 9.0을 선택했다. 그리고 서버 목록에서 식별자로 쓰일 Server name만 지정해주고 다음으로 넘어간다.
서버에서 운용할 프로젝트를 선택하고 Add를 클릭한다. 프로젝트가 오른쪽 목록으로 넘어간 것이 확인되었으면 Finsh로 창을 종료한다.
정상적으로 서버가 생성되었다면 프로젝트 목록에 Servers 폴더가 생성된다. 그리고 위와 같이 방금 생성한 서버에 대한 설정 파일이 담긴 폴더가 생성되어 있는 것을 볼 수 있다. 생성한 Server name에 맞는 폴더를 열어 server.xml에 들어간다.
server.xml 수정 전server.xml 수정 후
하단 끝으로 내리면 위와 같은 설정을 볼 수 있는데 여기서는 Context Path를 수정할 수 있다. 컨텍스트 패스란
웹 어플리케이션 이름으로서 클라이언트가 서버에 접속할 때 IP, Port 다음으로 식별 대상이 되는 웹 어플리케이션의 이름을 말한다. 서버에 URL을 요청했을 때 네트워크에서ip로 물리적인 컴퓨터를 찾고 컴퓨터에서 Port 번호로 서버를 식별, 컨텍스트 패스로 웹 어플리케이션을 식별하여 최종적으로 도달하게 되는 것이다.
context path의 기본 값은 프로젝트를 생성할 때 입력했던 패키지 명 끝 파트로 결정된다. 이 값을 그대로 두면 접속할 때마다 포트번호 뒤에 "/ku_develog"(본 프로젝트 패키지명 기준)를 붙여줘야 하는데 테스트에 걸리적 거리기 때문에 루트 패스("/")만 남기고 지워주겠다. 사용하고 싶다면 그대로 둬도 되고 "path" 값을 수정하여 사용해도 된다.
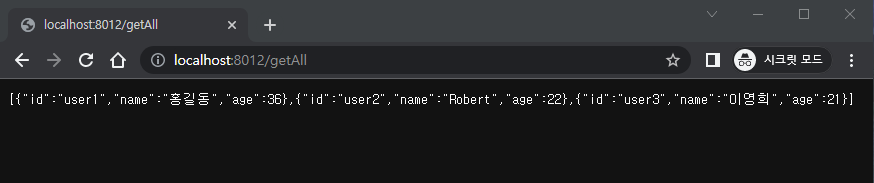
이것으로 데이터를 요청할 때 "http://localhost:8080/ku_develog/getAll"에서 "http://localhost:8080/getAll"로 간결하게 호출할 수 있게 되었다.
서버를 생성했다면 포트를 변경해 줄 필요가 있다. 오라클과 톰캣은 기본적으로 같은 8080 포트를 쓰고 있기 때문에 초기 포트가 8080이라면 충돌을 일으키게 된다. Servers 탭에서 방금 생성한 서버를 더블 클릭하고 창 하단에서 Modules를 클릭하면 위와 같은 화면을 볼 수 있다. 여기서 우측의 HTTP/1.1의 포트 번호를 현재 컴퓨터 내에서 사용하지 않는 포트 번호로 변경한 후 저장한다.
앞서 스프링과 오라클이 연동된 것을 확인했다. 이 상태에서 바로 JDBC를 사용할 수도 있지만 JDBC를 보다 편하게 사용할 수 있도록 MyBatis를 연동해보자. 해야 할 작업을 요약하면 다음과 같다.
DTO, DAO, Service, ServiceImpl 패키지 생성
MemberDTO.java 작성
MemberDAO.java 작성
MemberService.java 작성
MemberServiceImpl.java 작성
mybatis-config.xml 작성
memberMapper.xml 작성
MemberController.java 작성
root-context.xml에서 mybatis 설정 파일 참조, mapper, DAO Scan 등 지정
패키지 구성
연동에 필요한 클래스들을 작성하기에 앞서 패키지를 위와 같이 미리 구성해놓도록 하자.
DTO class
package com.tistory.ku_develog.dto;
public class MemberDTO {
private String id, name;
private int age;
public String getId() {
return id;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setId(String id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return new StringBuilder().append("{id=").append(id).append(", name=")
.append(name).append(", age=").append(age).append("}").toString();
}
}
Member 테이블과 대응될 데이터 클래스를 작성한다. 테이블과 대응되지만 동시에 클라이언트 간의 데이터 전송에도 사용되기 때문에 둘을 따로 구분하지 않고 DTO 이름으로 생성했다. 이 데이터 클래스는 테이블과 매칭될 것이기 때문에 테이블이 가진 모든 속성을 멤버 변수로 가져야 한다.
DAO Interface
package com.tistory.ku_develog.dao;
import java.util.List;
import com.tistory.ku_develog.dto.MemberDTO;
public interface MemberDAO {
public List<MemberDTO> getAll();
public MemberDTO getMember(String id);
public boolean insertMember(MemberDTO memberDto);
public boolean deleteMember(String id);
public MemberDTO updateMember(MemberDTO memeberDto);
}
DAO 인터페이스에는 DB에 접근할 때 사용할 메서드를 작성한다. 인터페이스지만 이 인터페이스는 구현(implements)되지 않고 뒤에서 생성하는 mapper.xml에서 작성하는 쿼리와 1:1로 매핑된다. 인터페이스의 구성을 보면 테이블의 모든 데이터를 읽어오는 getAll, 특정 id와 일치하는 데이터를 읽어오는 getMember, 그리고 데이터 삽입, 삭제, 수정 등을 수행하는 메서드가 존재한다.
DAO를 작성할 때 주의해야 할 것이 있는데 하나의 DAO Interface는 반드시 하나의 테이블에만 매핑되어야 한다는 것이다. 프로젝트에 다른 테이블을 추가로 사용해야 한다면 그 테이블에 대응하는 DAO를 추가로 생성해야 한다. 데이터베이스에 접근하는 객체라는 의미의 DAO(Data Access Object)가 접미사로 붙지만 마이바티스가 적용된 프로젝트에는 Mapper를 붙이기도 한다.
Service interface
package com.tistory.ku_develog.service;
import java.util.List;
import com.tistory.ku_develog.dto.MemberDTO;
public interface MemberService {
public List<MemberDTO> getAll();
public MemberDTO getMember(String id);
public boolean insertMember(MemberDTO memberDto);
public boolean deleteMember(String id);
public MemberDTO updateMember(MemberDTO memeberDto);
}
서비스는 비지니스 로직을 처리하기 위한 클래스로서 이 인터페이스는 서비스 클래스가 구현해야 할 메서드를 정의한다.
혹시 서비스 인터페이스와 DAO 인터페이스가 똑같음을 눈치챘는가? 여담으로 나는 처음 마이바티스가 적용된 예제를 따라해봤을 때 서비스 인터페이스와 DAO 인터페이스의 구조, 선언된 메서드가 완전히 같은 것을 보고 큰 혼란에 빠졌었다. 아예 같은 구조에 이름만 다른데 굳이 두 개의 인터페이스가 존재할 필요가 있는 건가 하는 생각이 머리를 지배했다. 한 두 명이 아닌 많은 블로그에서 비슷한 구조를 띄고 있었기 때문에 분명 의미가 있을거라 생각하고 스프링의 구조, MyBatis의 구조, MVC로 나누어진 구조를 제대로 공부하고 나서 보니 그제서야 왜 두 인터페이스가 같은지 깨달았다.
이유는 프로젝트의 규모가 매우 작기 때문이었다. 현재 이 프로젝트는 예제이기 때문에 Member에 대한 DAO, 서비스, 컨트롤러만 작성되어 있다. DAO는 테이블 하나에서 데이터를 읽어 오는 메서드만을 정의하기 때문에 한정적이지만 서비스는 테이블 하나에 얽매이지 않고 비지니스 로직을 처리하기 위해 지금 예제보다 더 많은 메서드를 정의할 수 있다. 하지만 이 프로젝트는 마이바티스를 어떻게 사용하는지 보여주기 위한 소규모 예제이기 때문에 별도의 메서드를 가지지 않고 둘 다 같은 구조를 띄게 된 것이다.
앞서 생성한 Service 인터페이스를 구현하는 ServiceImpl 클래스다. 이 클래스에서는 비지니스 로직을 처리하기 위한 코드를 작성하게 되며 비지니스 로직을 처리하기 위해서 DAO를 사용하여 데이터베이스에 접근, 데이터를 읽어올 수 있다. 서비스에 작성한 메서드들은 컨트롤러에서 호출된다.
사용된 어노테이션
Service : 클래스 레벨에서 이 어노테이션을 선언하면 스프링 컨테이너에 bean으로 등록된다. 파라미터로 bean 이름을 별도로 지정할 수 있는데 지정하지 않을 경우 클래스 이름을 카멜 표기법으로 변환하여 사용한다.
Autowired : 스프링에서 지원하는 DI 어노테이션으로, 멤버 변수 레벨에서 사용할 수 있다. 선언한 멤버 변수의 클래스 타입과 일치하는 bean이 스프링 컨테이너에 있다면 멤버 변수에 의존성을 주입해주는 역할을 한다. 코드를 보면 MemberDAO 객체에 대해 초기화 작업을 수행하지 않은 채로 객체를 사용하고 있는데 일반적인 자바 코드라면 Null Point Exception을 일으켜야 정상이지만 Autowired를 통해 정상적으로 의존성이 주입되었다면 에러를 일으키지 않는다.
Transactional : 이름에서 유추할 수 있듯이 트랜잭션에 관한 어노테이션으로 이 어노테이션이 적용된 메서드는 트랜잭션 처리된다. 앞서 pom.xml에서 트랜잭션에 관한 의존성을 주입(spring-tx)하였고 어노테이션으로 사용하기 위해서 root-context.xml에서 tx:annotation-driven을 사용해 선언적 트랜잭션 제어를 활성화하였다.(어노테이션 기반으로 트랜잭션 설정하는 것을 선언적 트랜잭션 이라고 봐도 된다.)
mybatis-config.xml 생성하기
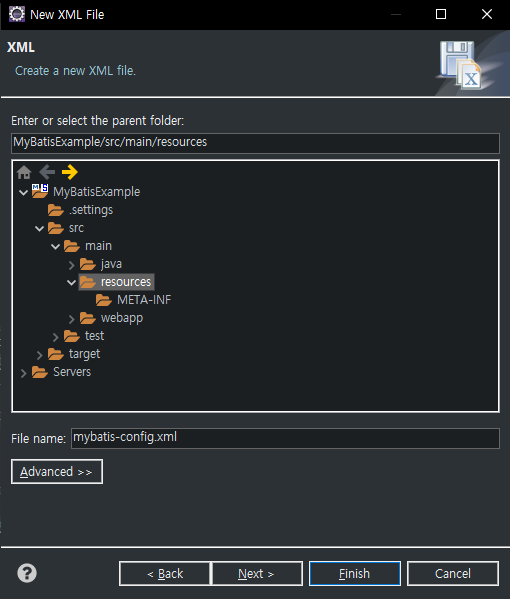
mybatis에 대한 설정 파일을 작성하기 위해 "src/main/resources" 폴더에 우클릭 후 위와 같이 "mybatis-config.xml" 파일을 추가한다. 이름을 바꿔도 되지만 이름을 바꿀 경우 root-context.xml에서 이 파일을 환경설정 파일로 지정할 때 이름도 맞춰서 적어줘야 한다.
파일을 생성하면 XML 선언부만 존재하는데 바로 아래 줄에 위와 같이 DTD 설정을 추가한다.
루트 앨리먼트인 configuration 태그에서는 mybatis에 관한 설정을 추가할 수 있다. 예제에 사용된 typeAliase는 클래스의 별명을 지정해줄 수 있는데 이 별명은 바로 다음 파트에서 작성할 "memberMapper.xml"에서 유용하게 사용될 것이다. xml은 java와 다르게 다른 클래스를 import 할 수 없기 때문에 앞서 만든 MemberDTO를 xml에서 사용하려면 "com.tistory.ku_develog.dto.MemberDTO"와 같이 풀 패키지명을 적어주어야 한다. 하지만 빈번하게 사용하는 클래스의 경우 코드가 길어짐은 물론 오타가 발생할 가능성도 있다. 하지만 위와 같이 별명을 부여하면 "memberDto"로 간편하게 사용할 수 있다.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tistory.ku_develog.dao.MemberDAO">
<select id="getAll" resultType="memberDto">
SELECT *
FROM member_t
ORDER BY id
</select>
<select id="getMember" parameterType="String" resultType="memberDto">
SELECT * FROM member_t
WHERE id = #{id}
ORDER BY id
</select>
<insert id="insertMember" parameterType="memberDto">
INSERT INTO member_t
VALUES(#{id}, #{name}, #{age})
</insert>
<delete id="deleteMember" parameterType="String">
DELETE FROM member_t
WHERE id = #{id}
</delete>
<update id="updateMember" parameterType="memberDto">
UPDATE member_t SET
name = #{name}, age = #{age}
WHERE id = #{id}
</update>
</mapper>
Mapper.xml은 테이블에 사용할 쿼리를 작성하는 곳이다. 루트 앨리먼트인 <mapper>를 보면 namespace 속성에 앞서 작성한 DAO 인터페이스가 지정되어 있는 것을 볼 수 있는데 이는 mapper.xml 파일 하나와 DAO 인터페이스 하나가 1:1로 매핑되어 사용된다는 것을 의미한다.
쿼리를 작성할 때 예제처럼 <select>, <insert>, <update>, <delete> 등을 사용한다. 사용된 태그들의 속성을 자세히 살펴보면 DAO 인터페이스에서 작성했던 메서드와 비슷한 꼴임을 알 수 있는데 id는 메서드의 이름, parameterType은 메서드가 받을 파라미터 타입, resultType은 메서드의 반환형이다. SQL의 결과에 따라 대충 끼워 맞춘 것이 아닌 DAO에 작성했던 메서드 하나하나의 구조와 정확히 매칭되고 있음을 알 수 있다.
id가 DAO에 작성한 메서드의 이름과 1:1로 매칭된다고 했으니 중복이 있어서는 안되며 DAO에는 없는 메서드 이름을 id로 사용하면 안된다. 네임 스페이스에 사용한 패키지 경로와 메서드 이름을 결합하면 "com.tistory.ku_develog.dao.MemberDAO.getMember()"와 같이 되기 때문이다.
메서드의 매핑에 관해 설명할 때 잠깐 나왔지만 resultType 속성은 쿼리 결과를 어떤 타입으로 매핑할 것인가를 결정하고 parameterType은 쿼리에 사용할 파라미터 타입을 결정한다. 여기서 마이바티스의 장점을 볼 수 있는데 기존 JDBC로 데이터를 조회하면 ResultSet 형태로 조회 결과를 받고 레코드를 하나씩 꺼내 결과를 파싱하여 데이터 객체에 세팅하는 과정을 수행해야 한다. 하지만 마이바티스는 모든 과정을 생략하고 파라미터 타입, 리턴 타입만을 지정하면 자동으로 결과를 가공해준다.
resultType의 데이터 타입은 기본 자료형, 커맨드 객체, 컬렉션 등을 지정할 수 있다. 위 예제에서 resultType에 대해 다소 특이한 부분이 있는데 쿼리 결과로 리스트를 반환하는 getAll과 객체 하나를 반환하는 getMember의 반환 타입이 같다는 것이다. getAll은 결과가 없거나 1개 이상의 결과를, getMember는 결과가 없거나 1개의 결과를 반환함에도 불구하고 왜 getAll에는 리스트를 사용하지 않았을까? resultType에 지정하는 타입은 레코드 하나를 저장할 타입을 지정하는 것이다. 마이바티스는 결과가 2개 이상일 경우 자동으로 결과를 리스트화해서 반환해주기 때문에 리스트의 타입만 제대로 설정해주면 된다.
속성 "parameterType"은 쿼리에 필요한 데이터 타입 혹은 객체를 지정한다. 메서드에서 작업을 처리하기 위해서 파라미터를 받는 것과 같다고 보면 되는데 실제로 MemberDAO에서 작성한 메서드의 파라미터 타입과 매핑되고 있음을 볼 수 있다. 파라미터를 SQL 문에서 사용하려면 #{parameter}와 같이 사용할 수 있으며 DAO에서 작성한 파라미의 이름을 사용할 수 있다. 또한 타입이 데이터 클래스인 경우 멤버 변수 이름을 쿼리에 그대로 사용하는 것도 가능하다.
컨트롤러는 클라이언트의 요청을 받는 역할을 한다. 클라이언트로부터 요청이 오면 디스패처 서블릿에 의해서 URL에 맞는 메서드가 호출될 것이다. 여기서는 오직 요청의 분리, 적절한 서비스 호출만을 생각하면 되기 때문에 앞서 작성한 서비스를 호출하여 비지니스 로직을 처리하고 결과를 클라이언트로 넘긴다.
사용된 어노테이션
RestController : 클래스 레벨에서 사용하는 어노테이션으로 @Controller와 @ResponseBody 어노테이션을 같이 사용한 것과 같다. 이 어노테이션이 사용되면 클래스 내 모든 메서드에 @ResponseBody 어노테이션이 적용된다.
ResponseBody : 여기서 사용되지는 않았지만 RestController로 인해 메서드 레벨에 선언되어 있는 것이나 마찬가지이기 때문에 짚고 넘어가자. 이 어노테이션이 적용되면 클라이언트와의 통신에서 XML, JSON 형태로 데이터를 주고 받는 것이 가능해진다.
Resource : 자바에서 지원하는 DI 어노테이션으로 bean의 이름을 특정해서 의존성을 주입받을 수 있다. 파라미터로 전달한 "memberService"는 앞서 MemberServiceImpl 클래스에 선언한 @Service 어노테이션으로 지정한 값으로, 컨테이너에서 "memberService"라는 key 값을 가진 bean의 의존성을 주입받겠다는 의미를 가진다. 이는 스프링 컨테이너가 key-value 형태로 bean을 관리하기 때문에 가능한 것이다.
RequestMapping : API를 호출할 때 사용되는 URL을 지정하는 역할을 하며 value는 호출할 url, method는 HTTP 통신에서 사용할 메서드 타입을 지정한다.
"src/main/resources"에 생성한 마이바티스 설정 파일, 매퍼 파일들을 sqlSessionFactory에 세팅한다. root-context.xml로 돌아와서 sqlSessionFactory에 "configLocation", "mapperLocations" 프로퍼티를 추가하고 파일의 경로를 지정한다.
configLocation은 mybatis의 설정 파일을 지정해줄 수 있지만 필수는 아니다. 지정해주지 않을 경우 디폴트 설정을 가진 마이바티스가 빌드된다. mapperLocations는 xml 파일 기반의 매퍼를 탐색한다. 프로퍼티의 값인 "/mapper/*.xml"은 아까 "src/main/resources"에 생성한 mapper 폴더에서 xml 확장자를 가진 모든 파일(* = 와일드 카드)을 매퍼 파일로 지정한다는 의미를 갖는다.
스프링 컨테이너에 bean 등록하기
마지막으로 앞서 생성한 controller, service, dao 클래스들을 스프링 컨테이너에 bean으로 등록해야 한다. 클래스 하나하나 bean으로 등록하는 방법도 있지만 Component Scan을 사용하는 것이 일반적이다. 컴포넌트 스캔은 특정 패키지 경로를 지정하여 지정된 패키지를 포함 하위 모든 패키지를 탐색하여 @Component가 적용된 클래스를 bean으로 등록시킨다. 앞서 사용했던 @Controller, @Service도 내부를 들여다 보면 @Component가 선언되어 있기 때문에 bean 등록 대상이 된다.
servlet-context.xmlroot-context.xml
servlet-context.xml에는 컨트롤러와 관련된 패키지를, root-context.xml에는 비지니스 로직과 관련된 패키지를 스캔한다.
servlet-context.xml에는 기본적으로 컴포넌트 스캔 태그가 존재하는데 스캔 경로(base-package)의 기본값으로 프로젝트를 생성할 때 입력한 패키지가 지정된다. 그리고 프로젝트를 생성할 때 입력한 패키지에는 HomeController가 자동 생성되기 때문에 처음 아무것도 설정하지 않아도 프로젝트를 실행하면 HomeController가 bean으로 등록되어 서버를 실행했을 때 "/" 경로로 동작 여부를 테스트할 수 있게 된다.
root-context.xml에서 사용한 태그를 자세히 보면 서비스는 component-scan이지만 dao는 "mybatis-spring:scan"인 것을 볼 수 있다. 이 스캔 방식은 지정한 패키지를 포함한 하위 모든 패키지를 탐색하여 발견되는 모든 인터페이스를 bean으로 등록해버리기 때문에 사용에 주의가 필요하다. 패키지 구분을 하지 않고 클래스를 한꺼번에 모아놨다면 bean으로 생성할 생각이 없었던 인터페이스들도 모두 bean으로 등록된다.
이로서 모든 연동 작업이 끝났다. 다음 포스팅에서는 프로젝트가 제대로 구성되었는지 테스트해 볼 것이다.
이 포스팅은 Spring과 mybatis, Oracle을 연동하는 과정에 대해 다룹니다. 프로젝트 생성부터 mybatis에 관한 초기 설정 및 연동, 테스트로 이어집니다. 테스트는 유저 정보를 가지는 테이블을 생성하고 더미 데이터를 넣어 데이터를 읽고 데이터를 추가하는 것으로 확인합니다.
과정도 과정이지만 단계가 넘어가면서 현재 단계가 이전 단계와 어떤 관계가 있는지, 생성하는 파일과 코드의 의미는 무엇인지 등에 대해서 자세히 서술해 보았습니다.
의존성 주입에 있어서는 생성자 주입이 아닌 어노테이션을 통한 자동 주입으로 구성하였습니다. 이 포스팅을 보는 사람이라면 스프링에 익숙치 않은 사람일 것이라 생각해 가장 간단한 자동 주입을 선택했습니다.
프로젝트 명 입력 후 템플릿에서 Spring MVC Project 선택 후 Next 선택.
"com.example.app_name"과 같이 패키지 명 입력 후 finish 선택. - package 이름 마지막은 클라이언트가 서버로 접속할 때 ip 주소, 포트 다음으로 구분되는 웹 어플리케이션 이름의 기본값이 된다. - 이 때 입력하는 패키지 명은 servlet-context.xml에 기본적으로 설정되는 component-scan 태그의 기본 값이 된다.
스프링 프로젝트가 정상적으로 생성되었다면 프로젝트를 진행하기 위해 필요한 의존성을 주입해야 한다. pom.xml 파일을 열고 아래에 있는 코드를 추가하거나 MavenRepository에 접속하여 원하는 버전을 찾도록 한다. 각 dependency 태그에 달린 주석에 있는 url로 접속해도 된다.
mybatis: 아파치에서 제공하는 자바 퍼시스턴스 프레임워크로 기존 JDBC를 사용할 때 꼭 처리해줘야 했던 작업(close, PreparedStatement, ResultSet 등)을 자동으로 해주고 처리 과정을 간소화 해준다. 또한 SQL과 Java 코드를 분리해서 관리할 수 있고 쿼리도 기존보다 쉽게 사용할 수 있다.
mybatis-spring: 스프링에서 mybatis와의 연동을 돕는 프레임워크.
spring-jdbc: 스프링에서 JDBC 처리를 도와주는 라이브러리.
spring-tx: 트랜잭션 처리를 위한 라이브러리.
commons-dbcp: Database Connection Pool을 사용하기 위한 라이브러리.
ojdbc6 : 오라클에서 제공하는 JDBC. 원래는 Maven에서 ojdbc를 지원하지 않아 수동으로 추가해줘야 했으나 20년 12월부터 지원하기 시작한 것으로 보인다.
spring-test: 스프링에서 JUnit과 같은 단위 테스트를 위한 라이브러리. (JUnit은 기본적으로 추가되어 있음)
annotation-api : Java 버전에 따라 더 이상 지원하지 않게 된 어노테이션(Resource 등)을 사용할 수 있게 해주는 API로 프로젝트에 설정한 자바 버전에 따라 필요하지 않을 수도 있으나 자바 버전이 높을 수록 추가해야 할 확률이 높다. 잘 모르겠다면 추가하자.
jackson-core, jackson-databind : 본 예제에서는 클라이언트와 상호작용 할 수 있는 화면, 즉 view를 만들어주지 않는다. URL로 데이터를 요청하고 쿼리 수행 결과만 JSON 형태로 받는 이른바 API 서버 역할을 하게 될 것이다. Jackson 라이브러리는 클라이언트에 대한 응답으로 JSON 또는 XML로 응답할 수 있도록 해준다.
추가적으로 jUnit의 버전을 수정한다. 스프링 프로젝트를 생성하면 jUnit에 대한 의존성이 기본적으로 주입되어 있는데 여기서 버전만 4.7 → 4.12 로 수정해준다.(JUnit의 버전은 낮을수록 최신이다.) 의존성 주입, 버전 수정이 모두 끝났다면 프로젝트를 우클릭하여 [Maven → Update Project]로 프로젝트를 업데이트해준다.
앞서 언급했듯 Maven은 원래 ojdbc를 지원하지 않았기 ojdbc.jar 을 다운받고 프로젝트에 수동으로 추가해주는 작업이 필요했었다. 혹시 모르니 수동으로 추가하는 방법도 아래 접어 놓겠다.
오라클 공식 홈페이지 Oracle JDBC Download에 접속해서 자신이 사용중인 오라클 버전에 맞는 ojdbc를 다운받는다. 필자는 가장 범용성이 좋은 ojdbc8.jar을 다운받았다.
버전에 따라 리스트 UI가 상이할 수 있음.
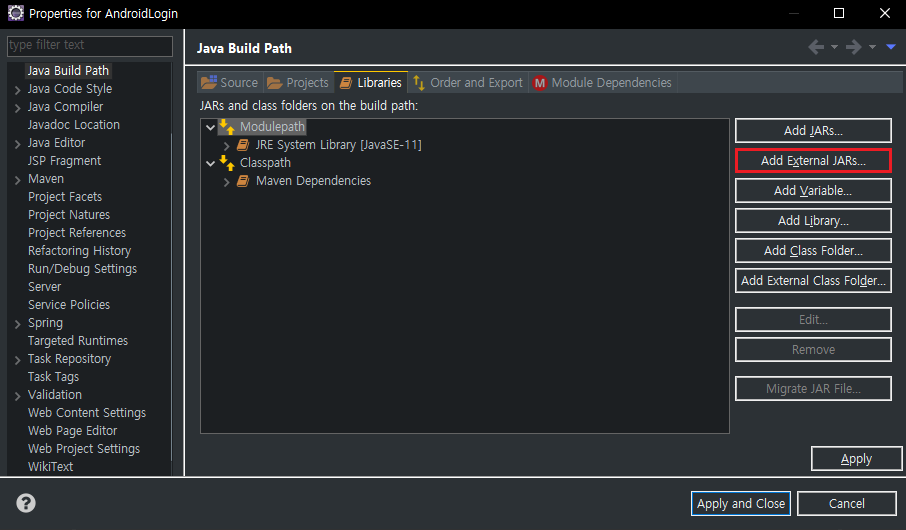
ojdbc를 다운받았다면 이클립스로 돌아와 프로젝트를 우클릭 하여 [Build path → Configure Build Path...]로 들어간다. 위와 같은 화면이 나오면 상단 탭이 "Libraries"인 것을 확인하고 Modulepath를 클릭, 우측의 "Add External JARs..."를 선택해 방금 다운로드한 ojdbc8.jar을 추가한다. 라이브러리 목록에 ojdbc가 추가되었다면 하단의 Apply를 눌러 저장해준다.
클릭하면 크게 보입니다.
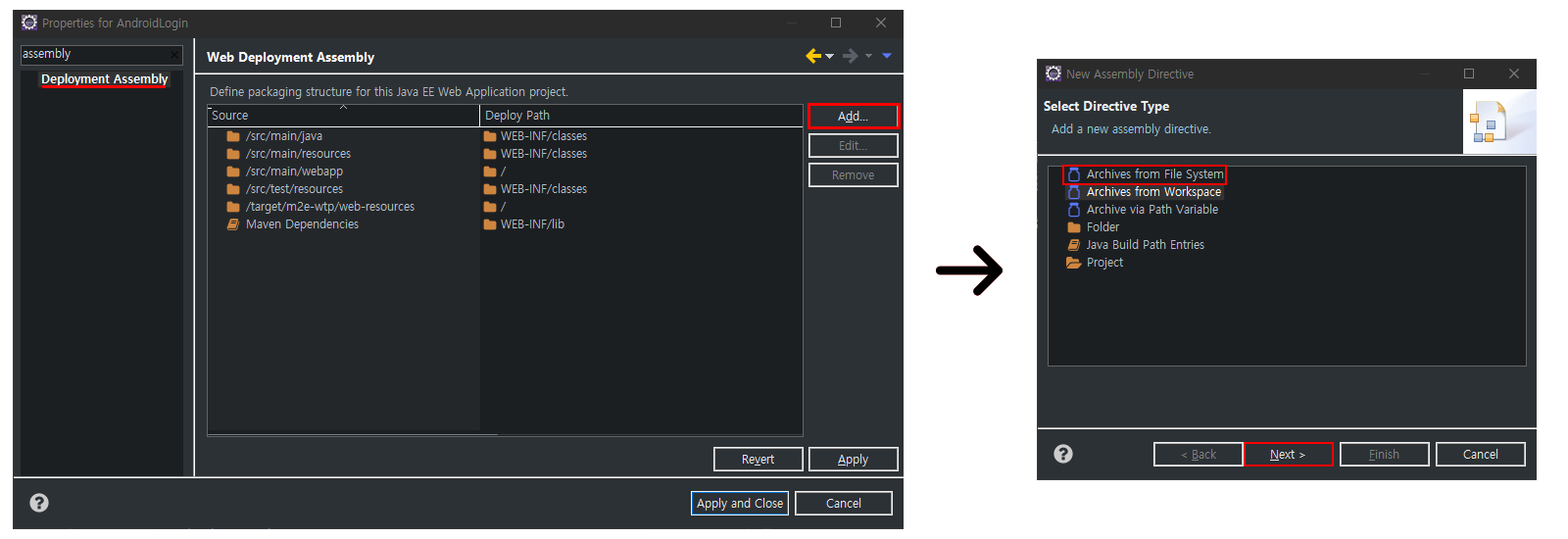
좌측 상단의 검색창에 assembly를 검색하면 나오는 "Deployment Assembly"를 클릭하면 위와 같은 화면으로 진입한다. 우측의 "Add.."를 클릭하고 나오는 창에서 "Archives from File System"을 선택하고 다음을 눌러준다.
다음 화면에서 우측의 "Add.."를 선택해 ojdbc를 추가해준다.
프로젝트로 돌아와보면 Referenced Libraries가 추가된 것을 볼 수 있고 펼쳐보면 안에 "ojdbc8.jar"이 있는 것을 확인할 수 있다.
bean 등록하기
스프링에서는 싱글톤 특성을 지니는 객체를 컨테이너에 등록하여 사용하며 컨테이너에 등록된 객체를 bean 객체라고 한다. 데이터베이스에 접근하는 객체는 특정한 서비스에서만 사용되는 것이 아니기 때문에 여러 서비스에서 호출하는 것이 가능해야 한다. 그렇기 데이터베이스에 접근할 객체를 bean으로 등록해 줄 것이다.
데이터베이스 연결에 관련된 객체들을 등록하기 위해서 root-context.xml에 들어간다.
처음 root-context.xml을 열었다면 위와 같이 기본적인 코드만 존재할 것이다. 여기서 하단 탭의 namespace를 누른다.
1. Marketplace로 들어가 Spring을 다운로드할 때 "Spring Tools Add-on..."을 다운로드 하였는지, 다운로드 했었다면 업데이트 항목이 있는지 확인한다. 설치하지 않았다면 설치해주고 Update 표시가 있다면 Update를 진행한다.
2. 프로젝트의 root-context.xml 파일에 우클릭하여 [Open-with → Other..]를 선택한다. 에디터를 선택하는 창이 나오는데 상단 체크박스가 "Internal editors"인 것을 확인한 후 spring을 검색하여 나오는 목록에서 "Spring Config Editor"를 선택하고 종료한다.
Namespaces를 누르면 위와 같은 화면을 볼 수 있는데 Namespaces의 목록은 pom.xml에서 주입한 의존성에 따라 구성된다. root-context에 추가하고자 하는 namespace를 선택하면 실제 코드 <beans>태그에 추가된다. 위 처럼 체크한 뒤 다시 하단 탭의 Source를 눌러 xml 코드로 이동한다.
정상적으로 수행됬다면 위와 같이 <beans> 태그가 수정된 것을 확인할 수 있다. 이제부터 bean 객체를 추가한다.
root-context.xml 에 위와 같은 코드를 추가한다. <bean> 태그는 기본적으로 id와 class를 가지는데 id는 식별자, class는 객체화하는 클래스를 나타낸다. xml로 생성한다 한들 결국 객체로 생성하는 것이기 때문에 객체화 할 클래스를 지정해주는 것이라고 보면 된다.
bean 객체 생성에 사용된 클래스를 살펴보자.
BasicDataSource: DBMS에 접속하기 위한 정보와 DBCP를 사용하기 위한 기본 설정을 초기화한다. JDBC를 사용할 때처럼 url, driver, user id, user password 등을 입력한다. 이는 SqlSessionFactory를 빌드할 때 참조될 것이다.(민감한 정보는 따로 빼내서 관리하는 것이 일반적이지만 예제이기에 하드 코딩으로 되어 있음을 주의.)
SqlSessionFactoryBean: 스프링에서 SqlSessionFactory를 빌드하는 컴포넌트로, SqlSessionFactory는 SqlSession을 생성 및 관리하는 역할을 한다. 위에서 생성한 dataSource를 참조하여 SqlSessionFactory를 빌드한다.
SqlSessionTemplate: MyBatis에서의 SqlSession을 대체한다. MyBatis의 SqlSession은 SQL구문을 실행하고 트랜잭션을 제어하는 역할을 하는데 Thread-safe 하지 않다는 문제점을 가지고 있었고 이 때문에 필요에 따라 Thread를 생성하고 새로운 인스턴스를 할당해야 했다. 하지만 mybatis-spring 프레임워크에서 제공하는 SqlSessionTemplate은 SqlSession을 Thread-safe하게 사용할 수 있어 따로 관리해 줄 필요가 없다. 추가적으로 constructor-arg 속성을 사용하였는데 이름에서 유추할 수 있듯이 생성자를 지정할 수 있다. 앞서 bean 태그는 스프링 컨테이너에 bean 객체를 생성한다고 했는데 SqlSessionTemplate 클래스는 인자가 없는 생성자가 없기 때문에 이 옵션을 필수로 작성해야 한다.
DataSourceTransactionManager: JDBC 기반의 트랜잭션 관리자다. 트랜잭션 관리자를 사용하려면 DataSource에 대한 의존 설정이 필요하기 때문에 앞서 생성한 dataSource 객체를 참조할 수 있도록 한다.
<tx:annotation-driven transaction-manager="id"> : id에 TransactionManager bean 객체의 id를 지정하면 어노테이션 기반의 트랜잭션을 활성화할 수 있다. 이 옵션을 활성화하면 프로젝트가 구동될 때 @Transactional이 적용된 메서드를 탐색하게 된다.
DataSource의 경우 DBMS에 연결하기 위한 설정과 DBCP(Database Connection Pool)를 사용하기 위한 초기 설정을 갖는데 필자는 dbms에 연결하기 위한 최소한의 정보인 driverClassName, url, username, password만을 입력했다. 오라클 DBMS를 설치하면서 별 다른 설정을 건드리지 않았으면 driver와 url은 그대로 사용하면 되고 username과 password는 본인이 사용 중인 db에 접속할 계정 정보를 입력해주면 된다. 필자는 예제로 가장 많이 사용되는 계정인 scott / tiger를 생성해 사용하였다. 이 외에 필요에 따라 initialSize, maxActive, maxIdle 등을 사용하여 커넥션 풀에 대한 프로퍼티를 추가할 수 있다.
DataSource, SqlSession Test
연결이 정상적으로 되었는지 확인하기 위해서 테스트를 수행한다. 스프링에서는 동적 웹 프로젝트에서 했던 것처럼 특정 파일만을 선택해서 서버에 올리는 것이 불가능하다. 프로젝트를 통째로 서버에 올려서 테스트해 볼 수도 있겠지만 기본적으로 의존성 주입이 되어 있는 jUnit을 사용하여 단위 테스트를 진행하도록 하자.
스프링 프로젝트에서는 테스트를 위한 디렉터리를 따로 제공하고 있다. "src/test/java"를 열고 테스트를 위한 클래스(JDBCTests.java)를 생성하고 다음 코드를 입력한다.
사용된어노테이션과 클래스는 아래 접은 글에 표시해두었으니 궁금하다면 펼쳐 보기 바란다. 테스트는 "DataSource 객체에서 커넥션을 얻어올 수 있는가"와 "SqlSessionFatctory에서 SqlSession 객체를 얻어올 수 있는가"를 확인한다. root-context.xml를 작성할 때 코드를 주의 깊게 봤다면 사용하려는 멤버 변수들이 앞서 등록한 bean 객체와 연관이 있음을 알 수 있다.
일반적인 try-catch-finally 구문이 아닌 try with resources구문을 사용하여 테스트한다. try( .. ) 안에는 자원을 사용한 후 반납할 필요가 있는 객체를 선언할 수 있는데 여기에 선언된 객체들은 작업( {..} )이 끝나면 자동으로 자원을 반납한다. 단, 자바 7 이후부터 지원하는 기능이기 때문에 버전이 낮다면 일반적인 try-catch-finally를 구성하도록 한다.
테스트를 수행하기 전에 파일을 저장하겠냐는 메시지 혹은 자동 저장이 되지 않기 때문에 파일을 수동으로 저장해야 한다. 테스트 할 메소드인 ConnectionTest에 커서를 위치한 후 우클릭을 하여 [Run as... → JUnit Test]를 눌러 테스트를 진행한다.
- JUnit의 테스트 범위를 확장할 때 사용하는 어노테이션이다. JUnit은 Java에서 단위 테스트를 지원하기 위한 프레임워크로, Spring에서 제공하는 프레임워크가 아니기 때문에 스프링에서 사용할 수 있도록 확장해주는 작업이다. - SpringJUnit4ClassRunner 를 지정해주면 테스트를 수행할 때 Application Context, 즉 스프링 컨테이너를 만들고 관리하는 작업을 해준다.
ContextConfiguration
반드시 RunWith와 같이 사용해야 하는 어노테이션이다. 그 이유는 이 어노테이션이 RunWith로 인해 생성될 Application Context 설정 파일 위치를 지정하는 역할을 하기 때문이다. 설정 파일은 기본적으로 servlet-context.xml, root-context.xml 등이 있는데 테스트하려는 bean에 따라서 하나만 넣거나 중괄호를 사용해 둘 다 넣어줄 수 있다.
Spring-test Annotation
Test
테스트를 수행 할 메서드를 지정한다.
Before
테스트를 수행하기 전에 수행될 메서드를 지정한다.
After
테스트를 수행한 후 수행될 메서드를 지정한다.
멤버 변수
DataSource : CP(Connection Pool)에 있는 Connection을 관리하기 위한 클래스. getConnection() 메서드를 호출하면 CP에서 Free 상태인 Connection 객체를 얻을 수 있다.
SqlSessionFactory : MyBatis에서 제공하는 SqlSession 객체를 가지고 있는 클래스.
Logger : Log4j에서 제공하는 로그를 출력하기 위한 클래스.
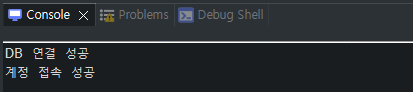
콘솔 탭과 JUnit 탭에 위와 같이 출력되었다면 테스트가 성공한 것이다. 커넥션 풀에서 얻어온 커넥션 객체의 정보와 SqlSessionFactory에서 얻은 SqlSession 정보가 출력된 것을 볼 수 있다.
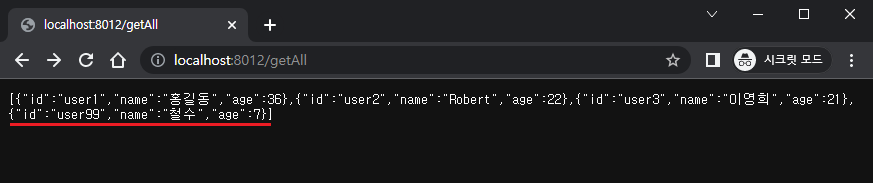
Spring과 오라클 간의 연동이 성공적으로 수행된 것을 확인하였다. 이제 테스트에 사용할 테이블을 생성하자.
테스트를 위한 회원 정보 table 생성하기
CREATE TABLE member_t (
id varchar(20) not null primary key,
name varchar2(30) not null,
age number not null
);
INSERT INTO member_t VALUES('user1', '홍길동', 36);
INSERT INTO member_t VALUES('user2', 'Robert', 22);
INSERT INTO member_t VALUES('user3', '이영희', 21);
테이블 생성은 Sql developer로 수행하였다. 다른 툴을 사용해도 되고 콘솔로 하는 것이 편하다면 그렇게 해도 된다. 테이블은 테스트 용으로 만들어진 임시 테이블인 만큼 간단하다. 아이디, 사용자 이름, 나이를 가지며 아이디가 주키가 된다. 빠른 테스트를 위해 미리 데이터를 삽입해놓도록 하자.
만약 목록에 사용중인 버전이 없을 경우 가장 하단에 있는 "JDBC Downloads page for older releases"를 선택한다. 필자의 버전은 11g인데 구버전 목록에도 없어서 적당히 12c를 선택했다.
ojdbc*.jar 파일 이 여러 개을 선택하고 다운로드 한다.
그래도 뭘 받아야할지 모르겠다면 가장 범용성이 높은 OJDBC8.jar을 다운로드한다.
이클립스에서 오라클 연동
이클립스에서 연동하고자 하는 프로젝트 우클릭 후 [Build Path → Configure Build Path...]를 선택한다.
상단 리본메뉴에서 "Libraries"를 선택하고 목록에서 "Modulepath"를 선택하면 비활성화 상태였던 우측 메뉴가 활성화 된다. "Add External JARs..."를 선택한다.
아까 다운받은 "ojdbc*.jar" 파일을 선택하고 돌아온 창에서 "Apply and close를 눌러준다."
프로젝트 내부에 "Referenced Libraries"가 추가된 것을 볼 수 있고 목록을 펼쳐보면 방금 추가한 파일의 위치를 가리키고 있는 것을 볼 수 있다. 위 사진으로 알 수 있듯이 파일을 복사한 것이 아니라 ojdbc 파일을 절대경로로 가리키고 있기 때문에 파일을 삭제하거나 다른 위치로 옮길 경우 참조가 불가능해지니 주의하자.
오라클 접속 테스트
import java.sql.Connection;
import java.sql.DriverManager;
public class Oracle {
public static void main(String[] args) {
Connection con = null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
String url = "jdbc:oracle:thin:@localhost:1521:xe";
String id = "scott";
String pw = "tiger";
System.out.println("DB 연결 성공");
try {
con = DriverManager.getConnection(url, id, pw);
System.out.println("계정 접속 성공");
} catch(Exception e) {
System.out.println("계정 접속 실패");
e.printStackTrace();
}
} catch (ClassNotFoundException e) {
System.out.println("DB 연결 실패");
e.printStackTrace();
} finally {
try {
if(con != null)
con.close();
} catch(Exception e) {
e.printStackTrace();
}
}
}
}
드라이버와 url은 그대로 사용하고 id와 pw는 본인이 오라클 DB에 접근할 때 사용하는 계정을 사용한다. DB 연결에 실패하면 드라이버가 제대로 연동되었는지 확인하고 계정접속에 실패했다면 id와 password를 확인한다.
오라클에서는 자사 DBMS를 사용한 개발과 관리를 간소화시켜주는 무료 통합 개발 환경으로서 SQL Developer를 제공한다. 필자는 Oracle 11gR2 Express Edition이 설치되어 있는 상태다. 오라클 버전에 따라 어떠한 옵션을 선택할 때 제한되거나 다르게 설정해야하는 것들이 있으니 "나는 왜 안되지?"라는 생각이 들면 설치된 버전, 환경에 따라 해결 방법을 찾아야한다.
위 링크로 접속하면 위와 같은 화면을 볼 수 있다. SQL Developer 소개 글 아래에 [SQL Developer]를 선택한다.
윈도우나 리눅스 등 다양한 플랫폼을 제공한다. 여기서 윈도우를 기준으로 현재 컴퓨터에 JDK가 설치되어 있지 않다면 위에 것을, 설치되어 있다면 아래 것을 다운받기 바란다.
다운로드받은 압축 파일을 해제하면 다음과 같은 파일이 나온다. 여기서 sqldeveloper.exe를 통해 설치를 진행하는데 설치가 완료되어도 시작 메뉴나 바탕화면에 따로 실행 아이콘이 생기지 않기 때문에 이 파일을 통해 sqldeveloper를 실행해야 한다. 때문에 압축을 해제한 파일은 따로 폴더를 만들어 보관하고 sqldeveloper 파일은 바로가기를 만들거나 시작메뉴에 직접 추가해서 사용하는 것을 추천한다.
sqldeveloper.exe를 실행시키면 위와 같은 화면을 볼 수 있다. 현재 JDK가 설치된 디렉터리의 경로를 삽입해주면 된다. 현재 환경이 32bit 아키텍쳐라면 "C:\Program Files(x86)\Java"아래에 있을 것이고 64bit 아키텍쳐라면 "C:\Program Files\Java"아래에 있을 것이다. 두 곳 모두 뒤져봤는데 Java 폴더가 없다면 설치되어 있지 않거나 설치할 때 기본 경로를 사용하지 않고 본인이 임의의 경로를 잡아서 다른 곳에 설치되어 있을 확률이 높다. 경로를 입력했다면 OK 버튼을 눌러 설치를 진행한다.
설치 도중 중간에 환경 설정을 임포트하겠냐는 창이 뜨는데 아니오를 눌러 무시해주면 바로 SQL Developer 화면이 출력된다. SQL Developer를 사용할 준비가 끝났다.
2. SQL Developer 접속 테스트 및 사용자 계정 생성
초기 화면에서 "XE"를 클릭하면 위와같은 화면이 나온다. 사용자 이름에는 "system"을, 비밀번호에는 오라클 DBMS를 설치할 때 입력한 비밀번호를 입력해준다.
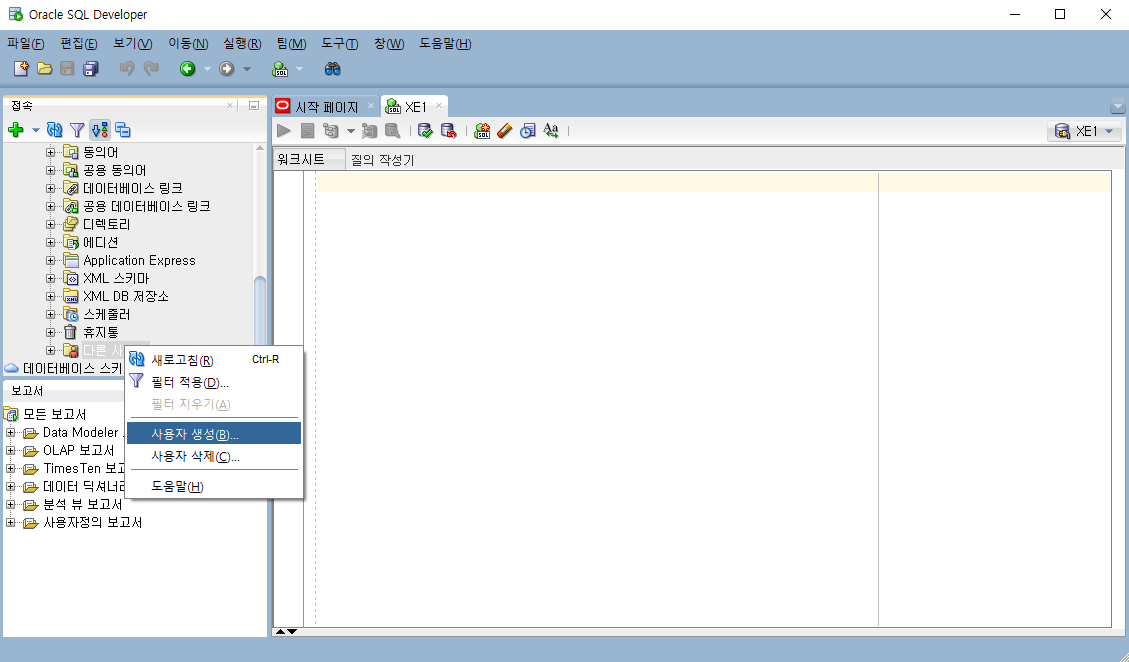
제대로 로그인이 되었다면 XE1이라는 이름으로 워크시트가 하나 켜졌을 것이다. 이대로 사용해도 상관없지만 사용자 계정을 하나 만들어서 사용해보자. 워크시트는 무시하고 좌측 메뉴에서 "다른 사용자"에 우클릭하여 "사용자 생성"을 선택한다.
사용자 이름과 비밀번호를 입력한다. 원하는 사용자명과 비밀번호를 입력해도 되지만 마땅히 떠오르지 않는다면 사용자 명에 "SCOTT", 비밀번호에 "tiger"를 추천한다. scott은 오라클 주식회사의 초대 프로그래머 Bruce Scott에서, tiger는 그가 기르던 고양이의 이름에서 따온 것으로 전세계의 많은 사람들이 오라클을 공부할 때 scott/tiger로 계정을 사용한다.
여기서 사용자 이름은 대문자로 입력해야 오류가 나지 않는다. 이후 로그인할 때에는 소문자로 입력해도 문제없다. 사용자 명과 비밀번호를 결정했다면 기본 테이블 스페이스와 임시 테이블 스페이스를 선택한다. 테이블 스페이스는 테이블의 정보가 저장될 공간을 뜻한다.
[버전이 11g가 아닐 경우] 현재 사용중인 DBMS가 11g라면 상관없지만 12c부터는 사용자 이름을 생성할 때 앞에 "C##"을 붙여야하는 규칙이 있다. 예를 들어 "scott"이라는 사용자를 생성한다고 하면 "C##SCOTT"으로 생성해야 한다는 것이다.
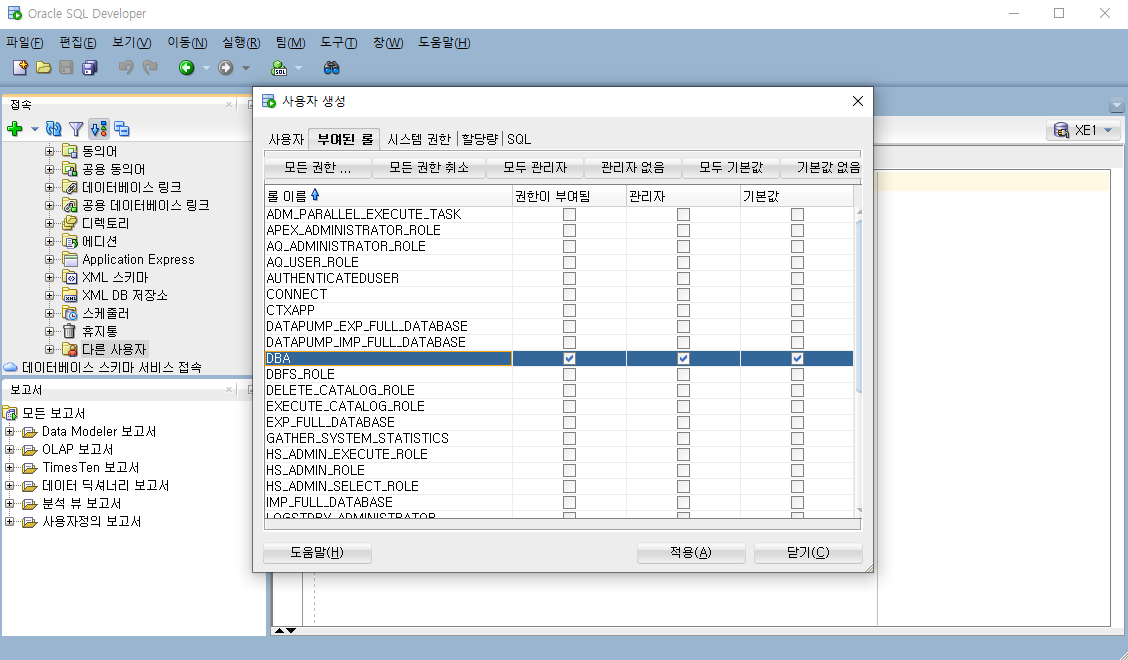
상단 탭에서 [부여된 롤]으로 들어오면 해당 사용자의 권한을 부여할 수 있다. DBA의 권한을 부여한다.
마지막으로 적용을 누르면 성공적으로 사용자가 생성된 것을 볼 수 있다.
좌측 상단 메뉴에서 + 를 클릭하면 위와 같은 화면이 출력된다. name, 사용자 이름, 비밀번호만 입력해주면 되는데 여기서 name은 좌측 접속 목록에 표시될 이름이니 별칭을 부여해도 된다. 그리고 사용자 이름과 비밀번호에 방금 생성한 계정의 이름, 비밀번호를 입력한다.
접속을 눌러 바로 접속해도 되고 테스트를 눌러서 접속 테스트를 시도해봐도 된다. 테스트를 눌러서 정상적으로 접속이 되면 좌측 하단에 "성공"이라는 문구가 출력될 것이다.
(Name 항목의 용도를 보여주기 위해 미리 생성 후 다시 접속 창을 열었기 때문에 스크린 샷에는 scott이 존재하는 것이고 원래는 없다.)
3. SQL Developer로 SQL 사용해보기
이제부터 타이핑하는 모든 명령문은 워크시트에 작성한다. 위처럼 명령문을 작성할 수 있으며 여러 개의 명령문을 작성한 뒤 모두 한 번에 실행시키거나 특정 명령문만 실행시키는 것이 가능하다. 모든 명령문을 실행시키는 경우 단축키 F5를 통해 수행할 수 있고 특정 명령문만 실행시키고자 하는 경우 해당 명령문에 키보드 커서를 옮긴 뒤 단축키 Ctrl + enter로 실행시킬 수 있다.
여기서 주의할 점은 모든 명령문이 끝나는 지점에 세미콜론을 표시해 줘야 한다는 것이다. 만약 워크시트 내에 명령문이 단 하나만 존재할 경우 세미콜론을 붙여주지 않아도 오류를 발생시키지 않지만 명령문이 2개 이상 존재할 때 명령문 끝에 세미콜론이 없다면 빨간줄이 그이게 된다.
하단 영역을 보면 스크립트 출력 탭과 질의 결과 탭이 있다. 스크립트 출력은 명령어의 수행 결과가 출력된다. 명령어를 수행함에 있어 오류가 있을 경우 에러 코드와 함께 오류 메시지를 출력하기 때문에 에러를 마주해도 구글링을 통해 에러를 쉽게 해결할 수 있다. 질의 결과 탭은 "SELECT"로 질의한 결과를 테이블 형태로 출력해서 보여준다.
마지막으로 사진처럼 워크시트의 각 라인에 행 번호를 붙여줄 수 있다. 이클립스나 비쥬얼 스튜디오를 사용해봤다면 라인 넘버가 있는 것이 에러 확인에 있어 편하다는 것을 알 것이다. 워크시트의 코드 영역에서 왼쪽의 빈 공간을 우클릭하여 "행 번호 토글"이라는 옵션을 클릭하면 라인마다 행 번호가 붙는다.
이제 간단한 명령문을 통해 사용법을 보자.
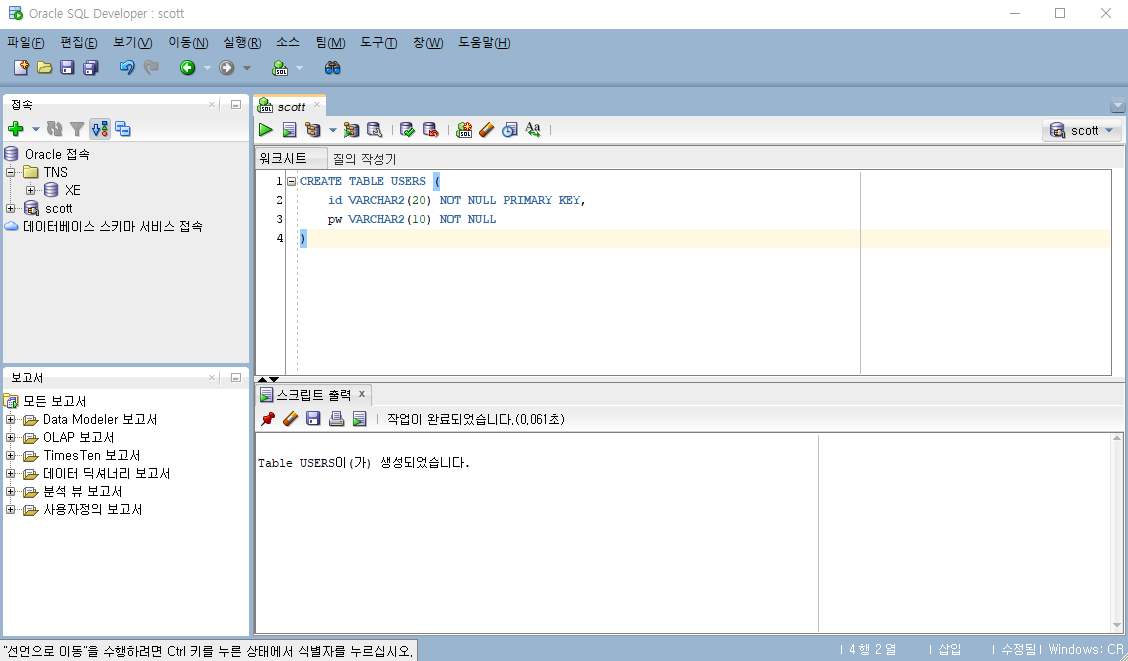
아이디와 비밀번호를 속성으로 가지는 users 테이블을 생성한다. CREATE 문을 구성한 후 단축키 Ctrl + Enter로 명령문을 수행한다. 명령어가 수행되면 아래 스크립트 출력창에 테이블이 정상적으로 생성되었다는 메시지를 볼 수 있다.
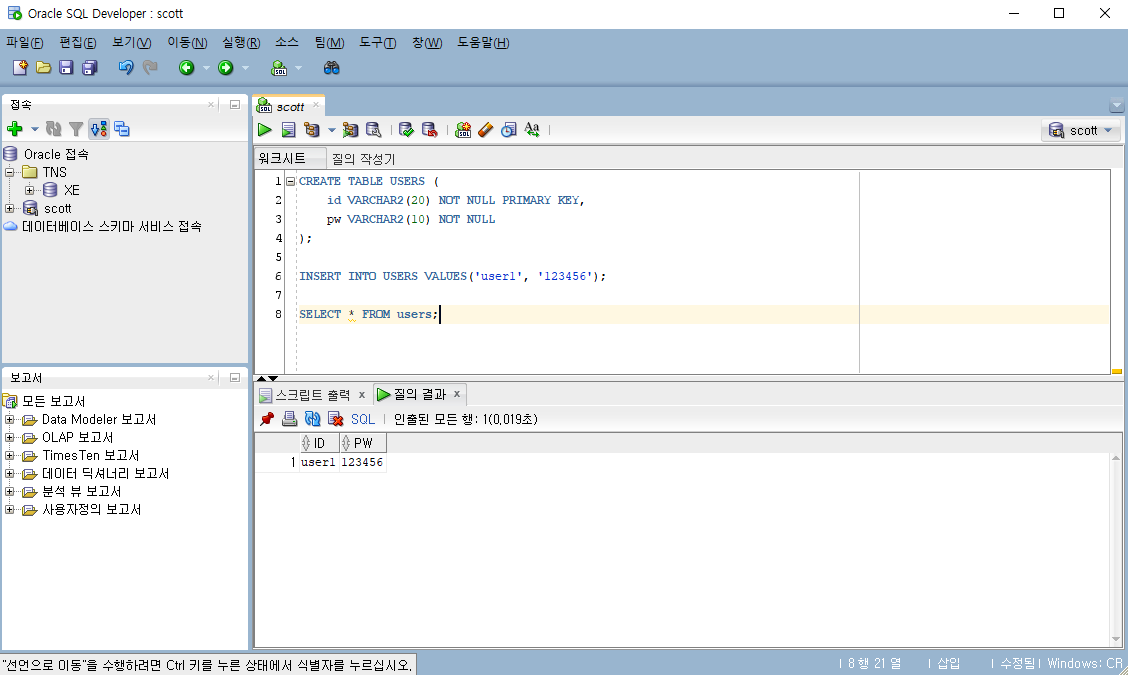
users 테이블에 id가 "user1"이고 pw가 "123456"인 데이터를 추가해보자. 위에서 말했듯 세미콜론만 잘 붙여준다면 이전에 입력한 CREATE문을 지우지 않은 채로 워크시트에 다음 명령문을 적을 수 있다. 단축키를 통해 명령문을 수행하면 스크립트 출력창에 행이 삽입되었다는 메시지를 볼 수 있다.
마지막으로 삽입한 데이터가 정상적으로 출력되는지 확인해보자. "SELECT * FROM users"는 users 테이블에 있는 모든 행을 읽어온다는 의미이다. 위에서 insert문을 통해 데이터를 삽입했기 때문에 users 테이블에 1개의 행이 있는 것을 볼 수 있다. 그리고 CREATE나 INSERT를 수행할 때에는 "스크립트 출력"창에 결과가 출력되었지만 데이터 질의를 수행했을 때에는 "질의 결과"창에 결과가 출력되는 것을 확인할 수 있다.
내가 개인 컴퓨터에서 사용하던 DB는 "Oracle Database 11gR2 Express Edition"이였는데 어느 순간부터 구글링을 해도 다운로드할 방법을 찾을 수 없어서 커뮤니티를 찾아보니 2020년 10월 31일 부로 지원이 종료되었다고 한다. 대체 버전으로 18c, 19c, 21c 등이 존재하지만 사용 용도에 비해 덩어리가 너무 큰 것이 사실이다. 나도 그렇지만 가볍게 사용하거나 학습 용도로 사용하기 좋아서 11g를 찾는 사람이 많다고 생각한다. 나는 11g 지원이 종료된 시점에서 파일을 구할 수 없어서 18c를 잠깐 썼는데 21년 중순 즈음부터 다운로드 링크가 돌아서 11g를 다시 사용하고 있다.
2021/01/20 기준으로 접속이 가능한 링크인데, 접속이 불가능해졌을 경우 댓글 남겨주시면 감사하겠습니다. 언제 또 사라질지 모르니 설치 후에 삭제하지 말고 저장해 놓는것도 좋을지도 모르겠네요.
위 링크에 접속하면 11g를 다운로드할 수 있는데 자신의 컴퓨터 환경에 맞게 다운로드하면 된다. 필자는 Windows 10 64bit 환경이기 때문에 첫 번째에 있는 파일을 다운받았다. 오라클에서 제공하는 것이기 때문에 다운로드하려면 로그인이 필요하다.
2. 압축해제 및 설치 진행하기
다운받은 파일의 압축을 풀면 아래와 같이 나온다. setup.exe를 실행해서 설치를 진행한다.
처음 화면을 넘기면 다음 화면에서 라이센스에 동의하겠냐는 문구가 나온다. 동의하고 Next를 클릭한다.
또 단일 선택지 화면에서 다음을 누르면 패스워드를 입력하라는 화면이 나오는데 여기서 입력한 패스워드는 SYS와 SYSTEM의 비밀번호가 된다. 사용하고자 하는 비밀번호를 똑같이 입력하고 다음 화면에서 Install을 눌러 설치를 진행해준다. 설치에 약 2~3분 정도 소요된다.
설치가 완료된 후 시작 메뉴를 살펴보면 위와 같이 설치가 완료된 것을 볼 수 있다.
오라클을 설치했다면 선택사항으로써 SQL Developer를 설치할 수 있다. DB에 접근할 때 CLI(Command Line Interface) 환경에서 할 수도 있지만 GUI 환경에서 편하게(?) 작업할 수 있도록 툴을 제공하는데 이것이 SQL Developer다. CLI로 SQL을 다루는게 어렵거나 검은 화면에서 SQL을 타이핑하는데 지쳤다면 SQL Developer를 설치해보는 것을 권장한다.