스프링 프로젝트를 생성하면 기본적으로 생성되는 web.xml에 대해서 알아보겠습니다. 이 포스팅은 Spring Starter Project가 아닌 Spring Legacy Project 기준으로 작성되었습니다.
들어가기 전에
- 포스팅에서 web.xml은 "Servers/server_name-config/web.xml"이 아닌 "src/main/webapp/WEB-INF/web.xml"이다.
- WAS를 Servlet Container로 부르기도 하지만 여기서는 서블릿을 관리하는 서버 사이드의 웹 어플리케이션으로 구분짓는다. 즉, WAS(혹은 톰캣)와 서블릿 컨테이너는 구분된다.
- Servlet Container = (Web Container)
- Spring Container = (Application Context, Application Container, IoC Container, Singleton Container)
web.xml
web.xml 파일은 배포 설명자(DD; Deployment Descriptor)라고 불린다. "src/main/webapp/WEB-INF/web.xml"에 위치한 이 파일은 웹 어플리케이션 실행 시 메모리에 로딩되는데 서버를 구동될 때 메모리에 로딩되어야 할 설정(객체) 등이 정의되어 있다. 스프링 프로젝트의 web.xml은 기본적으로 Context Loader Listener와 Dispatcher Servlet에 대한 설정이 정의되어 있다. 기본 설정 외에도 필요에 따라 서블릿, 필터를 정의할 수도 있다.
웹 어플리케이션은 반드시 단 하나의 web.xml을 가져야 하기 때문에 아파치 톰캣 + 스프링 프레임워크로 구성된 서버에서는 톰캣의 web.xml과 스프링 프레임워크의 web.xml 총 2개가 생성된다.
web.xml에 정의 해놓은 설정들은 서버가 구동될 때 메모리에 올라가는 것도 있고 사용자의 요청에 따라 호출되었을 때 비로서 메모리에 올라가는 것도 있다. 이 부분에 대해서는 아래에서 흐름에 맞게 설명할 것이다.

[6~9] root-context.xml의 경로를 파라미터로 등록한다. 여기서 정의된 파라미터는 Servlet Context 객체에서 읽어올 수 있다.
- <context-param> 태그를 사용하면 스프링 컨테이너에서 사용 할 수 있는 파라미터를 선언할 수 있다.
- <param-name> 태그는 <context-param>에 대한 식별자를 지정한다.
- <param-value> 태그는 <context-param>에 대한 값을 지정한다.
[11~13] Context Loader Listener는 위에서 생성한 "contextConfigLocation" 파라미터를 참조하여 루트 컨텍스트를 생성한다.
[15~23] <servlet> 태그 내에 생성된 "contextConfigLocation" 파라미터를 참조하여 Dispatcher Servlet에 관련된 컨텍스트를 생성한다.
- <servlet> 태그는 Servlet을 상속받아 작성된 클래스를 서블릿으로 등록한다.
- <servlet-name> 태그는 서블릿의 식별자를 지정한다.
- <servlet-class> 태그는 서블릿으로 등록할 클래스를 지정한다. 반드시 패키지 이름까지 풀네임으로 적어줘야 한다.
- <init-param> 태그는 서블릿 초기화에 사용될 파라미터를 설정한다. 이 경우 디스패처 서블릿이 객체화되고 초기화를 위해 init() 메서드가 호출될 때 참조될 설정 파일의 경로를 파라미터 값으로 설정하며 1개 이상의 파라미터를 설정할 수 있다. <context-param>과 다른 점은 <servlet>내에 선언된 만큼 참조 범위가 해당 서블릿 내로 제한된다.
- <load-on-startup>태그는 주어진 값이 1 이상일 경우 서버 구동 시 서블릿이 바로 메모리에 올라갈 수 있도록 한다. 여기에서 값은 서블릿의 로드 순서(혹은 우선순위)를 나타내는데 숫자가 높을수록 우선순위가 낮다.
[25~28] : 앞서 [15~23]에서 등록한 Dispatcher Servlet에 대한 URL을 매핑한다. <servlet-mapping>은 web.xml에 등록한 서블릿 이름과 클라이언트로부터 받는 url을 매핑할 수 있다.
- <servlet-mapping> 태그는 등록한 서블릿에 대한 URL을 매핑하기 위해 사용한다.
- <servlet-name> 태그는 매핑할 서블릿 이름(위에서 설정한 식별자)을 지정한다.
- <url-pattern> 태그는 지정한 서블릿이 어떤 URL에 매핑될 것인지를 지정한다. 기본적으로 루트("/")에 매핑되어 있기 때문에 모든 URL이 매핑 대상이 된다. 평소 와일드 카드 문자(*)에 익숙한 사람이라면 '/'가 아니라 '/*' 아닌가라는 생각을 할 수 있지만 '/'를 사용하는 것이 맞다.
Context Loader Listener

<context-param>은 서블릿 컨텍스트에 파라미터를 등록할 수 있으며 필요에 따라 파라미터를 추가할 수 있다. 자바에서 변수를 선언하듯 param-name으로 이름을 부여하고 값으로 설정 파일(root-context.xml)의 경로를 부여하여 파라미터 이름을 통해 설정 파일에 접근할 수 있게 한다.
Context Loader Listener는 스프링 컨테이너를 생성하고 컨테이너에 루트 컨텍스트를 생성한다. <listener-class>값을 보면 컨텍스트 로더 리스너가 추상적인 개념이 아닌 실제 클래스임을 알 수 있고 패키지 명을 보면 스프링 프레임워크에서 제공하는 클래스임을 알 수 있다. 컨텍스트 로더 리스너는 org.springframework.context.ApplicationContext 인터페이스를 구현하는 것으로 스프링 컨테이너를 생성한다. 또한 이 때 위에서 생성한 파라미터 contextConfigLocation을 읽어서 설정 파일(root-context.xml)에 정의된 bean을 컨테이너에 생성하는 것이다.
web.xml에서 둘은 연관성을 찾아볼 수 없지만 ContextLoaderListener 클래스가 상속받고 있는 ContextLoader 클래스를 들여다보면 일부 메서드가 ServletContext를 통해 contextConfigLocation 파라미터에 접근하는 것을 볼 수 있다.
Dispatcher Servlet
- web.xml에서 초기화, 실행되도록 정의되어 있다.
- 디스패처 서블릿 역시 Servlet이기 때문에 서블릿 컨테이너에 생성된다.
- 모든 요청은 컨트롤러로 가기 전에 디스패처 서블릿을 거쳐야 한다.
- 컨트롤러들이 공통적으로 수행해야 하는 작업을 처리한 뒤 적절한 컨트롤러로 요청을 넘긴다.
- 디스패처 서블릿이 공통된 작업을 처리해주기 때문에 각 컨트롤러는 비지니스 로직 처리에만 집중할 수 있다. 이렇게 하나의 컨트롤러를 놓고 모든 요청을 한 곳으로 집중, 일괄 처리하는 디자인 패턴을 Front Controller 패턴이라 한다.
- 요청에 해당하는 컨트롤러를 찾는 작업은 HandlerMapping에게 위임하고 결과를 반환받는다. 다시 HandlerMapping에게 받은 데이터를 HandlerAdapter에게 전달하여 컨트롤러 실행을 위임한다.
- 컨트롤러는 실행 결과로 JSON, XML, View 등을 반환하는데 View가 반환될 경우 사용자에게 표시될 View 파일(*.html, etc)의 이름을 전달받는다. 이 데이터를 ViewResolver 객체에게 전달하여 실제 View를 찾는다.
- 모든 서블릿을 파싱하여 Map 형태(Key-Value)로 관리한다.
- 1개 이상의 디스패처 서블릿이 존재할 수 있으며 디스패처 서블릿은 각자의 서블릿 컨텍스트를 갖는다.

디스패처 서블릿은 "src/main/webapp/WEB-INF/web.xml"에 정의되어 있다. <servlet-class>의 값을 보면 디스패처 서블릿은 추상적인 개념이 아니라 클래스로 존재한다는 것을 알 수 있고 패키지 명을 보면 자바가 아닌 스프링 프레임워크에서 제공하는 클래스면서 디스패처 서블릿 역시 서블릿의 한 종류라는 것을 알 수 있다.
디스패처 서블릿도 컨텍스트 로더 리스너와 마찬가지로 설정 파일의 경로를 파라미터로 생성, 참조하여 스프링 컨테이너에 컨텍스트를 생성하게 된다. 스프링 컨테이너에 컨텍스트를 생성하는 것은 다름이 없지만 생성 과정에서 다소 차이가 있는데 디스패처 서블릿은 org.springframework.web.context.WebApplicationContext 인터페이스로 컨텍스트를 구현한다. 또한 컨텍스트 로더 리스너와 달리 파라미터가 서블릿 태그 내부에 선언되었기 때문에 디스패처 서블릿이 생성하는 컨텍스트의 bean들은 외부에서 참조가 불가능하다는 차이가 있다.
설정 파일을 파라미터로 선언함에 있어 차이를 보이는 것은 그냥 어쩌다보니 그렇게 된 것이 아니라 의도적으로 설계된 것이다. 계층 아키텍쳐에서 비지니스 로직을 처리하는 객체들이 View에 해당하는 객체들을 참조할 수 없도록하고 반대는 가능하도록 참조 관계를 나눈 것이다. 이는 부모 관계로도 표현할 수 있는데 root-context.xml에 정의된 bean들이 부모, servlet-context.xml에 정의된 bean들이 자식에 해당한다. 부모 클래스는 자식 클래스에 있는 변수, 메서드의 존재를 알 수 없기 때문에 접근이 불가능한 반면 자식 클래스는 부모 클래스를 물려받았기 때문에 부모 클래스에 있는 변수, 메서드에 접근할 수 있다. 왜 이렇게 나누어졌느냐고 묻는다면 이유는 간단하다. 컨트롤러는 비지니스 로직을 처리하기 위해서 서비스를 호출해야만 하는 반면 서비스나 DAO는 뷰를 직접 호출할 일이 없기 때문이다.
Dispatcher Servlet이 메모리에 올라가는 시점
일반적인 서블릿이 메모리에 올라가는 시점, 즉 객체화되는 시점은 클라이언트로부터 요청이 발생했을 때다. 어노테이션 혹은 web.xml에 등록되어 있다가 해당 서블릿에 대한 요청이 발생하면 객체화되고 int()을 호출하여 초기화된다. 디스패처 서블릿도 서블릿이지만 일반적인 서블릿과는 달리 웹 어플리케이션 구동 시 객체화되는데 일반적인 서블릿을 등록하는 방식과 다르지 않음에도 불구하고 서버 구동 시 바로 객체화되는 이유는 <load-on-startup> 태그 때문이다. 이 태그의 값이 0보다 클 경우 서블릿 컨테이너가 생성 및 초기화될 때 해당 서블릿이 같이 초기화된다.
디스패처 서블릿이 서블릿과 달리 서버 구동 시에 객체화되어야 하는 이유는 무엇일까? 서블릿은 기본적으로 해당 서블릿에 대한 요청이 발생해야만 객체화되는데, 이 말은 어떤 서블릿은 서버가 구동되고 나서 한 번도 호출되지 않을 수 있다고도 해석될 수 있다. 반면 디스패처 서블릿은 프론트 컨트롤러이기 때문에 어떠한 요청이라도 반드시 호출된다. 서블릿은 최초 요청이 발생했을 때 메모리에 올리는 시간이 소모되기 때문에 요청이 있는 한 반드시 호출되는 디스패처 서블릿을 사전에 등록하여 요청이 발생했을 때 메모리에 올리는 시간을 없애주고 즉시 사용을 보장해주는 것이다.
Dispatcher Servlet 동작 과정
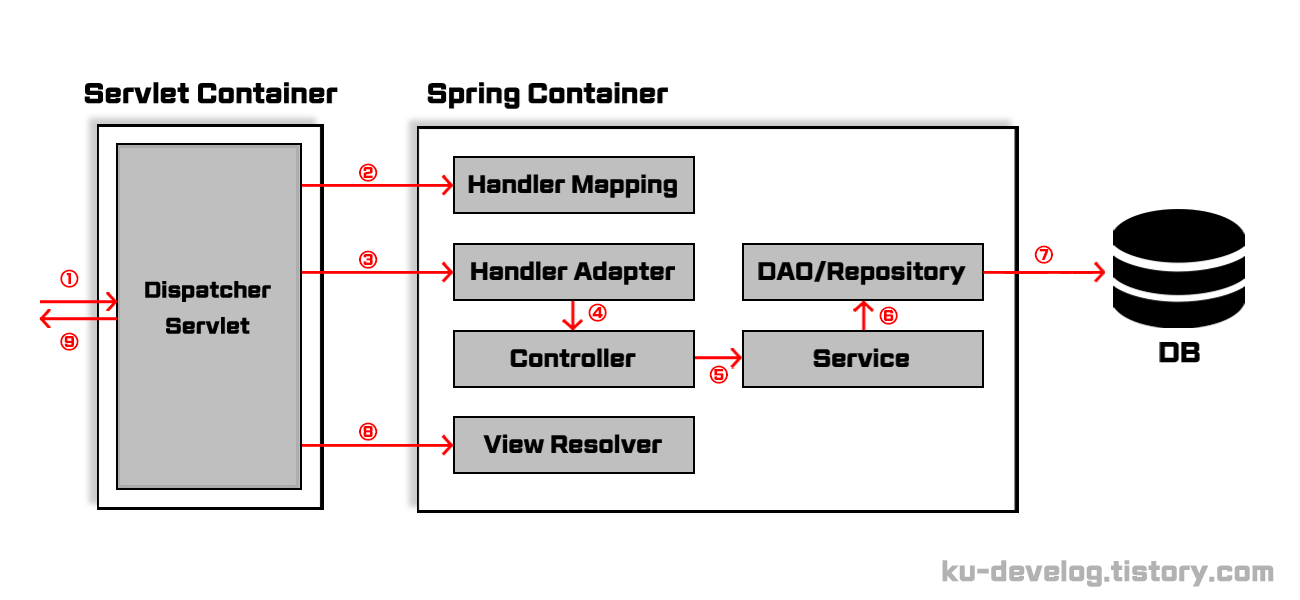
디스패처 서블릿의 요청 처리과정을 이미지로 나타내었다. 기본적으로 존재하는 컴포넌트와 필수 요소만으로 최소 구성하였기 때문에 Filter, Interceptor 등은 없다.
- 클라이언트로부터 요청 발생, 웹 서버를 거쳐 서블릿 컨테이너로 요청 전달
- HandlerMapping 객체에게 요청 URL에 대한 컨트롤러의 존재 여부 확인, 존재한다면 컨트롤러의 이름을 요청.
- HandlerAdapter를 호출하여 컨트롤러 실행을 위임
- HandlerAdapter는 요청받은 URL과 매핑되는 Controller 호출.
- Controller는 비지니스 로직을 처리하기 위해 적절한 Service 호출.
- Service는 비지니스 로직 처리에 필요한 데이터를 요청하기 위해 DAO/Repository 호출.
- 데이터베이스에 데이터 조회 및 수정.
- 비지니스 로직을 처리한 결과가 View(의 이름)일 경우 ViewResolver를 호출하여 View를 반환.
- 클라이언트로 요청 결과 전달.
'서버 > 스프링(Spring)' 카테고리의 다른 글
| [Spring] 정상적으로 동작하던 스프링 서버 외부 접속 실패 (0) | 2023.01.30 |
|---|---|
| [Spring] Component-scan 이란 (0) | 2022.07.14 |
| [Spring] STS4, Oracle, myBatis 연동하기 (3/3) (0) | 2022.06.05 |
| [Spring] STS4, Oracle, myBatis 연동하기 (2/3) (0) | 2022.06.04 |
| [Spring/error] SpringJUnit4ClassRunner.class not found (0) | 2022.06.02 |




