[자바] Collection Framework
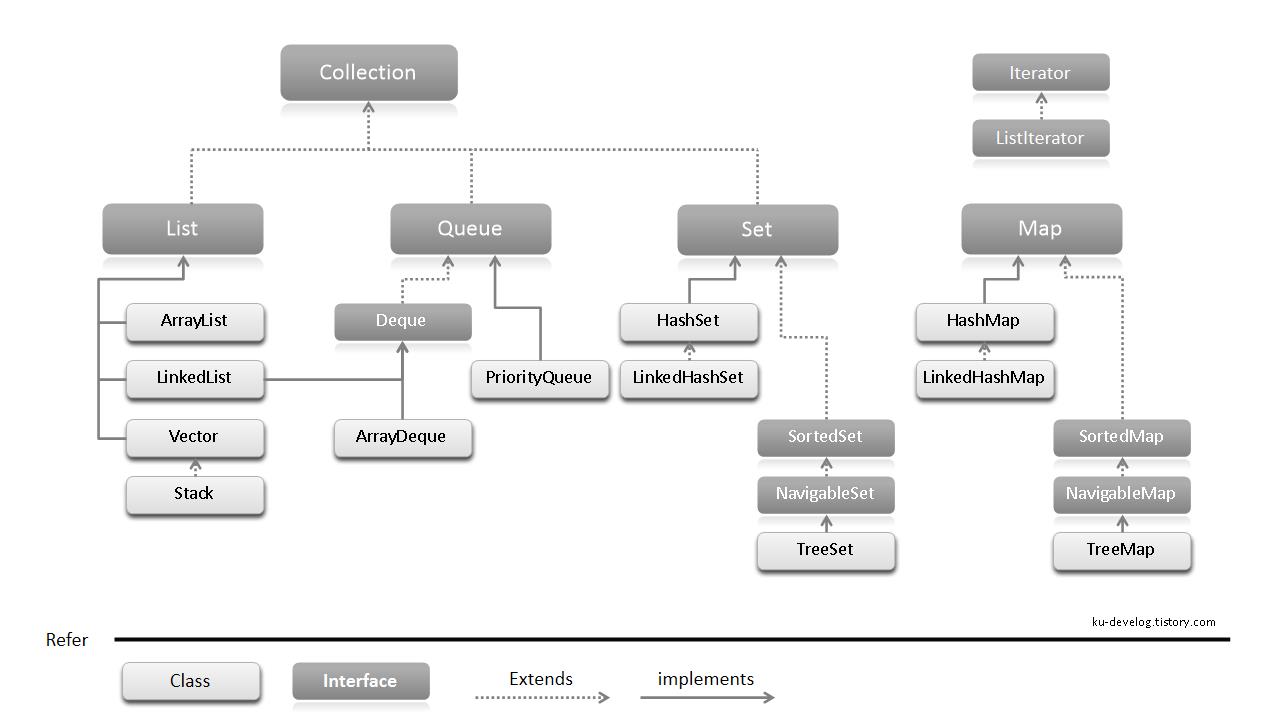
자바에서는 데이터를 쉽고 간단하게, 상황에 맞게 효율적으로 저장할 수 있도록 표준화 된 클래스(자료구조)를 제공하는데 이러한 클래스의 집합을 컬렉션 프레임워크라고 한다. 큰 범주로 보면 List, Set, Queue, Map 등으로 나눌 수 있다. 알고리즘도 그렇듯 어느 상황, 환경에서든 항상 뛰어난 성능을 보이는 자료구조는 없다. 모두 장단점이 있고 좋은 상황과 나쁜 상황이 있기 때문에 상황에 맞는 자료구조를 골라서 사용해야 한다.
인터페이스 별 특징
- Collection : 주로 컬렉션 간의 이루어지는 작업을 담당한다. 컬렉션끼리 데이터를 복사하거나, 서로 가진 데이터를 비교하는 등 컬렉션 사이에 일어나는 메서드들을 다룬다.
- List : 순서가 있는 데이터의 집합으로 중복되는 데이터를 허용한다.
- Set : 순서가 없는 데이터의 집합으로 중복된 데이터를 허용하지 않는다.
- Map : List, Set과 다른 저장방식을 취한다. Key-Value 쌍으로 데이터를 저장한다. 키는 중복을 허용하지 않지만 값은 중복을 허용한다.
- Queue : 데이터가 들어온 순서대로 출력되는 FIFO 구조를 갖는다. 대표적인 예로 운영체제 스케쥴러가 있다.
- iterator : 컬렉션에 데이터를 읽어오기 위한 인터페이스다. 루프를 돌려 get 메서드로 데이터를 순서대로 읽어올 수도 있지만 해당 인터페이스를 구현하면 for-each문으로 데이터를 읽어올 수 있다.
Collection에서의 Interface와 class의 관계
Interface는 설계도일 뿐이다. 어떤 인터페이스를 구현(implemets)하는 클래스는 반드시 설계도(interface)에 나와있는 메서드를 구현(override)해야 한다. List는 Collection을 상속(extends)받고 ArrayList는 List를 구현(implements)하였기 때문에 ArrayList는 Collection과 List가 가진 메서드들을 반드시 구현해야한다.
이렇게 해서 얻는 효과는 무엇일까? Collection이 가진 주요 메서드로 isEmpty(), clear() 등이 있는데 이 메서드들은 Collection을 구현한 ArrayList, HashMap, Stack 등 모든 자료구조에서 공통적으로 사용할 수 있다. 자료구조의 특성에 따라 내부에서 처리하는 방식은 다르지만 사용할 때 데이터가 비어 있는지 확인할 땐 isEmpty()를, 데이터를 초기화할 땐 clear()를 사용한다는 것은 동일하다.
다음과 같은 상황을 가정해보자. 어떤 기능을 구현할 때 ArrayList를 사용해서 데이터를 저장했었지만 구현해놓고 보니 LinkedList가 더 적합해보여서 LinkedList로 변경하려 한다. ArrayList는 내부적으로 배열을 사용하고 LinkedList는 Node를 사용하는데 구조가 전혀 다름에도 불구하고 각 자료구조 고유의 메서드를 몇 개 제외하면 Collection, List를 구현할 때 사용한 메서드를 둘 다 똑같이 구현하고 있으므로 최소한의 수정으로 자료구조를 교체할 수 있는 것이다.

또한 선언시에 자료구조 타입을 상위 인터페이스인 List로 선언할 경우 코드를 전혀 수정하지 않고 위처럼 한 번만 수정해서 자료구조를 바꾸는 것도 가능하다. 다만 이 경우에는 ArrayList가 가진 고유의 메서드를 사용하지 않았다는 가정이 필요하다. 즉 ArrayList를 사용할 때 Collection, List 등 LinkedList와 공통적으로 구현한 인터페이스에 속한 메서드만 사용한 경우, 위와 같은 한 번에 자료구조 교체가 가능하다는 것이다. 이를 업 캐스팅이라 한다.